

Get your free ebook


According to Coursera, “Data engineering is the practice of designing and building systems for collecting, storing, and analyzing data at scale.”
Sounds good at first glance. But let’s try to understand data engineering in simpler terms.
Businesses generate a lot of data, such as customer feedback, operational information, stock price influences, and sales performance. Unfortunately, much of this information is complex and difficult to understand. Hence, businesses need a solution that will help them collect and analyze raw data as well as derive practical applications that they can leverage to thrive.
This is where data engineering comes in.
A subdiscipline of software engineering that entirely focuses on transportation, transformation, and storage of data, data engineering involves designing and building pipelines that convert data into usable formats for end users.
Data engineering forms the foundation of any data-driven company, which is why data engineers are in high demand these days. However, this role demands a lot of data literacy skills.
Data engineering is a skill that’s been steadily rising in demand over the years. Data engineers are responsible for making raw data usable for further data-driven work by data scientists, business analysts, and all other end users within an organization.
The responsibilities of data engineers include but are not limited to:
In a nutshell, business intelligence, data science, or any other data-related teams are the end users of data engineering teams.
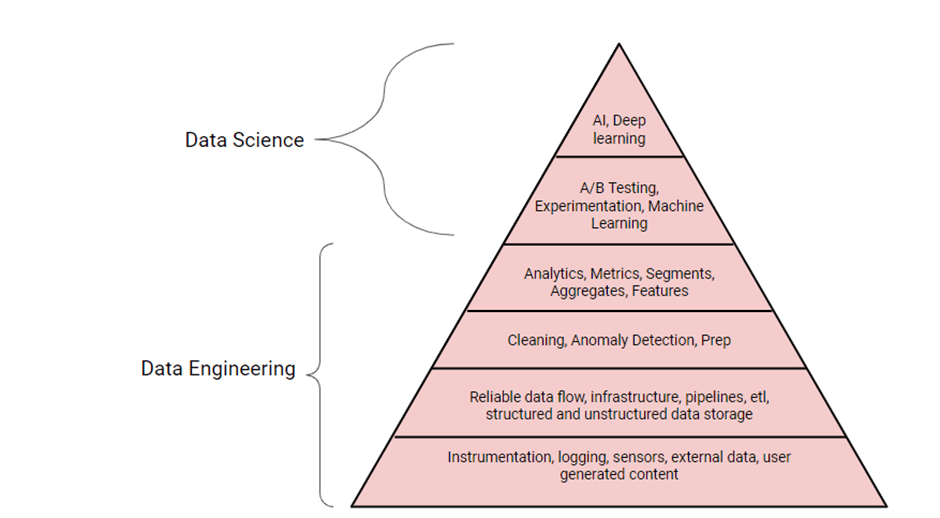
A lot has been written about data engineering vs. data science in the past, like in the image above created by Terence Shin.
In reality, they are two complementary skills. Data engineering makes data reliable and consistent for analysis, while data science uses this reliable data for analytical projects such as machine learning, data exploration, etc.
This works very much the same way humans put their physical needs before social needs. Often, companies have to satisfy a few prerequisites that generally fall under the data engineering umbrella to create a foundation for data scientists to work on.
Therefore, it is correct to say that data scientists rely on data engineers to gather and prepare data for analysis. As a matter of fact, we could even make the claim that there can be no data science without data engineering. At least, that’s what the theory says, and it’s also the reason why Terence Shin wrote, “Data engineering is the foundation for a successful data-driven company.” Who are we to argue with that?
Nevertheless, some of you might disagree with the image or the statement above, since there are a lot of data scientists out there who perform data engineering (DE) tasks, as well as plenty of data engineers who do machine learning. So, we will leave it to you to decide what you choose to believe.
Now that we have a better understanding of data engineering itself, it’s time to dive deeper into understanding the typical data engineering tasks, fields of action, data pipelines, etc.
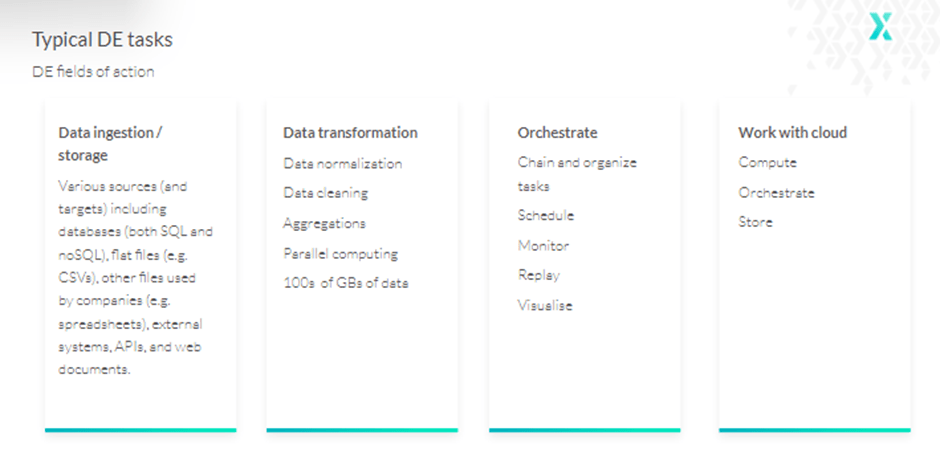
The first step of a data engineering project lifecycle—data ingestion—involves moving data from various sources to a specific database or data warehouse where it can be used for data transformations and analytics.
Storage is also worth mentioning here, since the core purpose of data engineering is connecting to various storage types, extracting data from it, and saving it.
One challenge with this is that data comes in various file formats such as comma, tab-separated, JSON, and column-oriented like Parquet or ORC files. So, data engineers often have to deal with both structured and unstructured data.
Additionally, this data might be present in various SQL and NoSQL databases as well as data lakes, or they might have to scrape data from websites, streaming services, APIs, etc.
As the name suggests, data transformation refers to converting data from one format to another. Typically, most data that is collected demands some sort of adjustment so that it aligns with the system architecture standards.
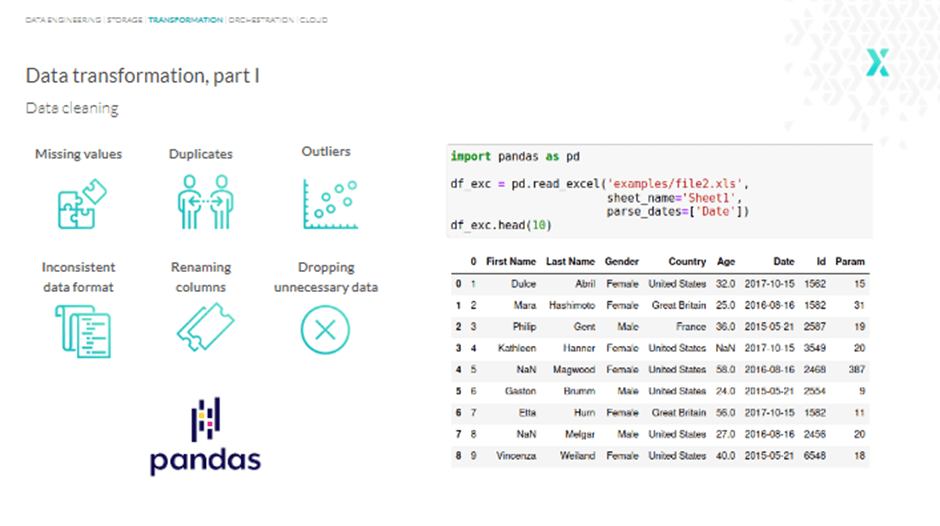
So, under transformation, a data engineer will perform data normalization and cleaning to make the information more accessible to users. This includes changing or removing incorrect, duplicate, corrupted, or incomplete data in a dataset; casting the same data into a single type; ensuring dates are in the same format; and more.
As all these transformations are performed on extremely large amounts of data, there also arises a need for parallel computing.
The last step is data orchestration—combining and organizing siloed data from various storage locations and making it available for data analysis—as data pipelines comprise several elements: data sources, transformations, and data sinks/targets.
Hence, rather than writing them as a large block of code, data pipelines are built from separate, relatively smaller pieces using different kinds of technologies.
To achieve this, a data engineer should connect the separate pieces, schedule the process, and sometimes make decisions based on incoming data, replay part of the pipeline, or apply parallelization to some parts. Performing all these tasks demands a larger and more efficient tool than, for instance, Crontab.
Finally, most modern data engineering tasks are performed in the cloud. Therefore, a data engineer will also require proper tools that work efficiently with the cloud.
As mentioned earlier, data ingestion is about gathering and storing data for further use. That brings us to the question, “How are different databases connected?”
SQLAlchemy is perhaps the most commonly used tool for connecting databases. An object-relational model library, it supports MySQL, MariaDB, PostgreSQL, Microsoft SQL Server, OracleDB, and SQLite. It consists of two distinct components: the Core and the Object Relational Mapper (ORM).
The Core is a fully featured SQL toolkit that allows users to interact with a wide range of DB APIs. In ORM, classes can be mapped to the database schema. The ORM is optional, but it is probably the main feature that makes SQLAlchemy so popular. Other connectors include:
Basically, every known database or data warehouse—whether it’s Snowflake Elastic or ClickHouse—has its own Python connector or at least recommends using a generic one. For websites and APIs, there are well-known request libraries that are often used in conjunction with BeautifulSoup—a helpful utility that allows you to get specific elements out of a webpage, such as a list of images.
There is also Scrappy, a tool that allows users to write small amounts of Python codes to create a “spider”—an automated bot that can go through web pages and scrape them. With the help of Scrappy, data engineers can download, clean, and save data from the web without additional hard work.
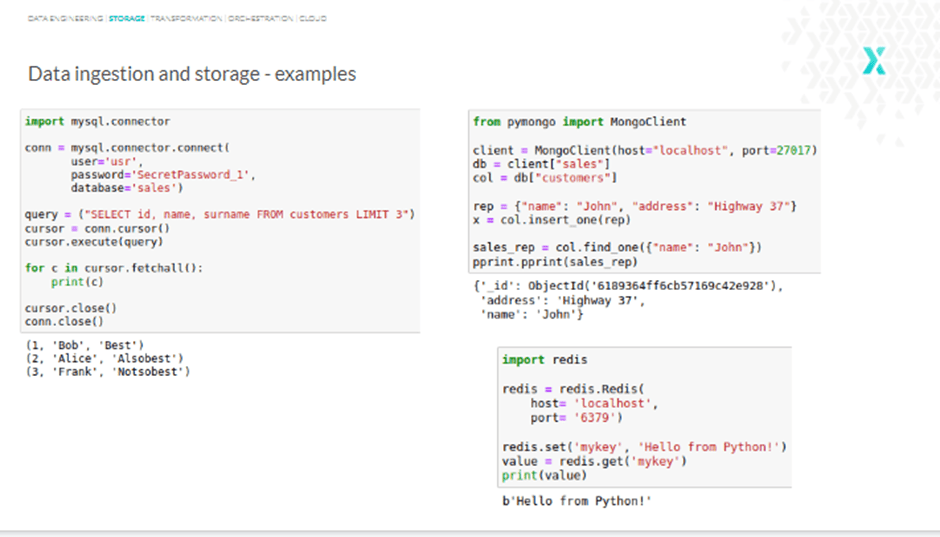
Getting started with a database is fairly simple. The steps are quite similar for most databases, with subtle variations. For instance, querying a MySQL database with a MySQL connector involves the following steps:
Similarly, when working with MongoDB, you create a client connection, set a database, set a collection, insert a sales representative, and in the final part, try to find one by name. With Redis, on the other hand, you create a connection, set a value, and get this value back by searching by key.
See, all it takes is a few lines of code to start working with most databases. However, it is worth remembering that storing your credential inside the code is a bad practice—always use config files.
Data scraping is a challenge in data engineering. However, BeautifulSoup can help.
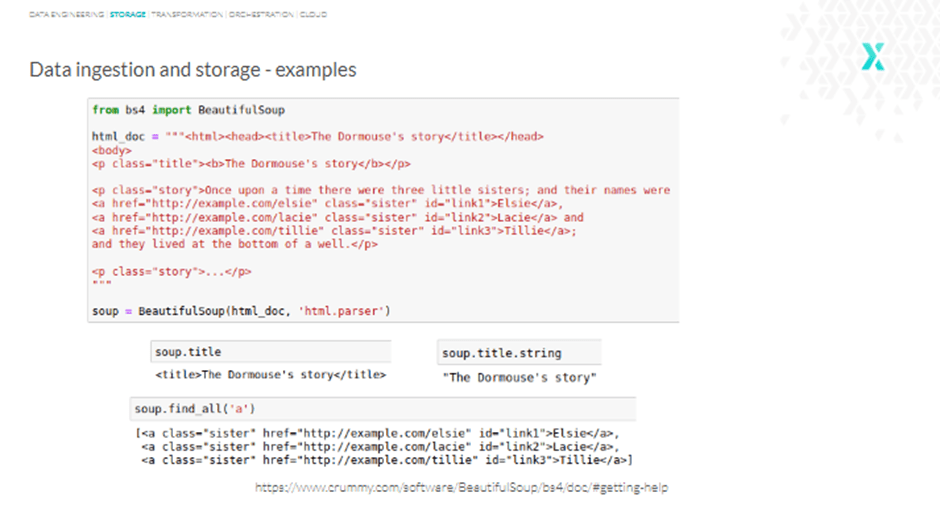
A Python package for parsing HTML and XML documents, BeautifulSoup is relatively easy to work with.
Take a look at the example below, and you will see that we use html.parser in the second line that gets the BeautifulSoup object to represent the document as a nested data structure.
Similarly, the title function can be used to get the title, title.string to get just the string, or find_all() to get all the tags and strings that match our filters.
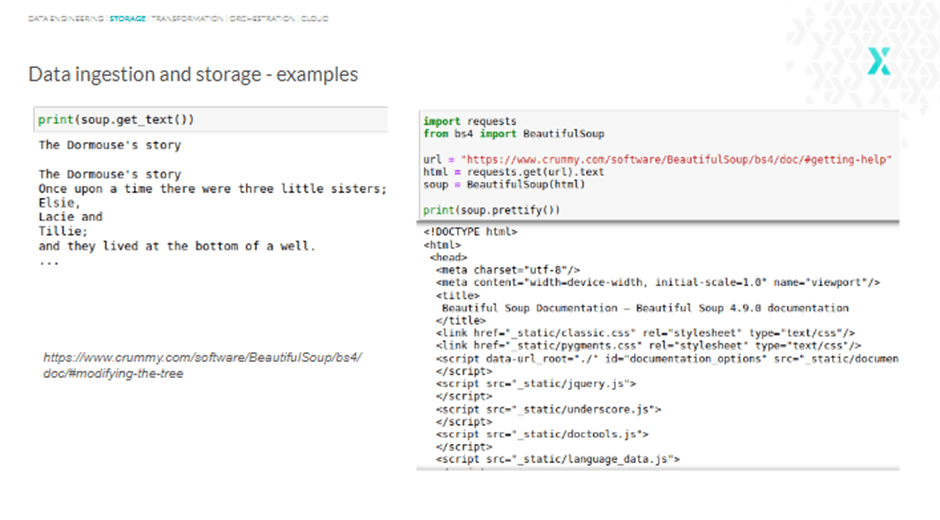
As the html.parser used in the last line is a built-in parser, no extra dependencies are required. However, if you are interested, here are two other parsers to keep in mind:
BeautifulSoup helps data engineers easily extract text from pages, modify or replace tags, insert new ones, etc. The HTML files from the internet can be fed into BeautifulSoup, and it will transform the document into a complex tree of Python objects.
Nevertheless, you only have to deal with around four objects: Tag, NavigableString, BeautifulSoup, and Comment.

Another issue during the data ingestion and storage phase is having to deal with the various file formats. This is where Pandas come in.
A software library written for Python, Pandas allows us to interact with almost every known file format. Still, for a few formats, there are only reader functions, like ORC, SAS, or SPSS, and for Latex (Lay-tech), there is only the writer. But the good news is that even if Pandas doesn’t directly support a file format, there is always some workaround solution on how that specific data can be read to Pandas dataframes.
As far as streaming services are concerned, Kafka is the ideal option. There are three predominant Python libraries that work with Kafka:
Confluent Python Kafka is perhaps the best option, since it was created by Confluent, the same people who developed Kafka. Additionally, PyKafka is no longer supported, though it can be seen in a lot of examples and articles.
For streaming services like Amazon Kinesis, there are dedicated Python libraries:
Data transformation involves changing, eliminating, or fixing a dataset’s incorrect, duplicate, corrupted, or inaccurate data. It can be a pretty tedious task. According to IBM Data Analytics, data scientists spend up to 80% of their time cleaning data.
But how is this process carried out?
Pandas can be used here, as it features a data manipulation function that can be used to access data and carry out data cleaning. However, there are several challenges remaining.
Before we move on to the challenges and solutions, take a look at the following table. Here we have some general information about customers, such as name, gender, country, etc.—including other fields like “date” and a column named “param.”
We could either use “na” or “null” to see the missing values, but it doesn’t happen immediately. So, adding an “any” function at the end can help.
However, what if we want to know the exact number of missing values for a specific column? Well, we can use “sum” instead of “any,” and we’ll get something like this:
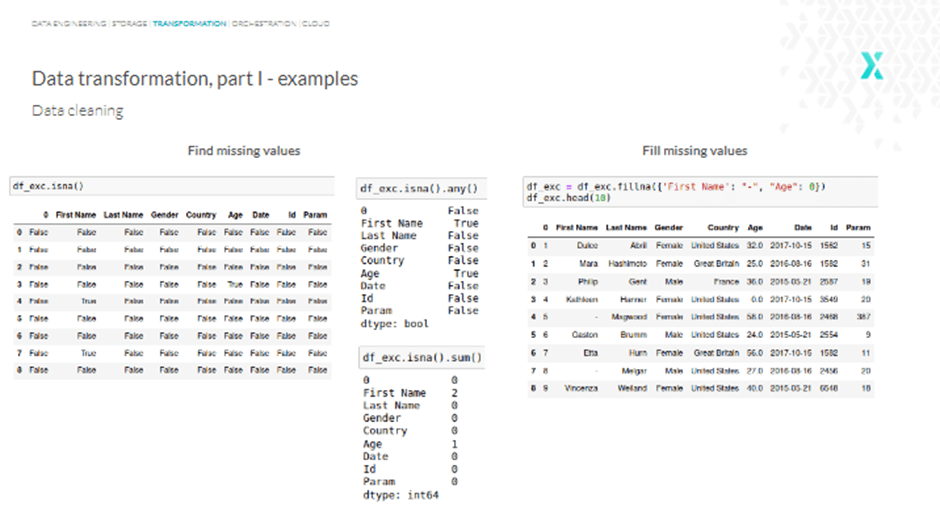
To fill missing values, use the “fillna” function, and for all the missing names, we get a dash, while the missing age is filled with “0.” Alternatively, we can also use drop rows with at least one or all NaN (Not a Number) values with the function “dropna,” and so on.
An even better way to find and fill missing values is to use Pandas.
In Pandas, missing data is represented by None and NaN. The various functions used to detect, remove, and replace null values in Pandas DataFrame include:
Beyond finding and filling missing values, Pandas can perform functions like counting, sums, averages, joining data, applying conditioning, and more. However, these are all basic functions. So, let’s move to something bigger: Apache Spark.
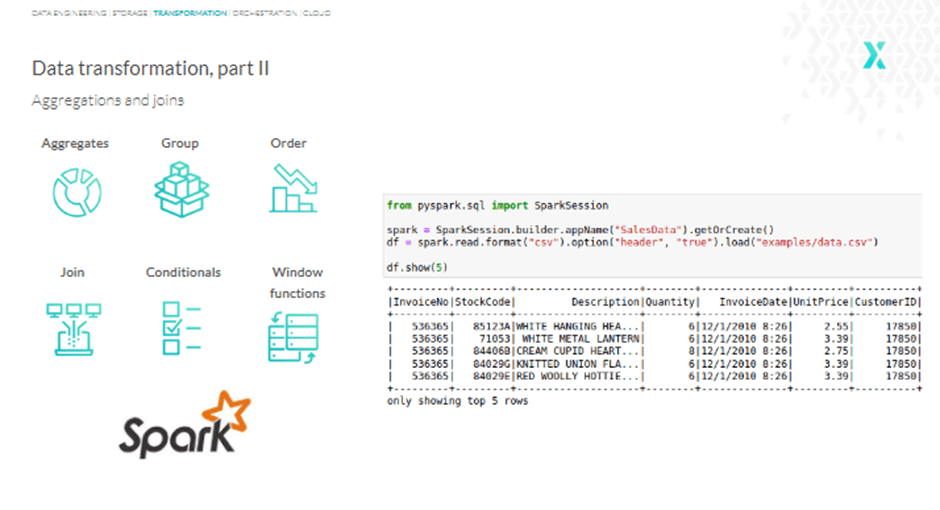
Apache Spark is an extremely powerful and fast analytics engine for big data and machine learning, particularly beneficial in accessing CSV files. Another important use case of Apache Spark is parallel processing; the tool is designed to process data in a distributed way.
Additional features include lazy evaluation and caching intermediate results in memory. So, if you are processing or transforming millions or billions of rows at once, Apache Spark with proper infrastructure is probably the best tool for the job.

Another tool we would like to bring to your attention is Dask, which in contrast to Apache Spark is a pure Python framework and does not aim to be a complete ecosystem.
Dask was built because libraries like NumPy or Pandas were not originally designed to scale beyond a single CPU or to work with data that does not fit into memory. Dask allows us to efficiently run the same code in parallel, either locally or on a cluster.
Now, when it comes to parallel processing strictly on one machine, Python has a threading and multiprocessing option.
Threads can’t do things in parallel, but they can do things concurrently. That means they can go back and forth between things, and as such are suitable for IO-bound tasks.
On the other hand, multiprocessing is designed to do things in parallel, so it’s convenient when we’ve got CPU-bound tasks, like doing aggregations on millions of rows or processing hundreds of images.
Let’s start this section by understanding the importance of orchestration tools.

Imagine a pipeline of tasks that should be run once a day or once a week. These tasks should be run in a specific order. However, they grow and become a network of tasks with dynamic branches called DAGs—Directed Acyclic Graphs. So, orchestration tools are essential to ensure data in DAGs flows in one direction, or in other words, to ensure it has no cycles.
But that’s not all. Other than organizing tasks into DAGs and scheduling them, we also often want to:
So, which Python-based tool should be used to address this challenge?

Well, you have plenty of options to choose from. You may use Apache Airflow, Dagster, Luigi, Prefect, Kubeflow, MLflow, Mara, or Kedro. Nevertheless, Airflow happens to be the most popular option, as it has a wide array of features. On the other hand, Luigi (designed by Spotify) and Prefect are much easier to get started with, though they lack some of Airflow’s features.
For instance, Airflow can run multiple DAGs at once and trigger a workflow at specified intervals or times. Also, it’s way simpler to build more complex pipelines, where, for example, we want one task to begin before the previous task has ended.
Additionally, Prefect is open-core, while Luigi and Airflow are both open-source.
Now, if you want an alternative for Airflow or any other workflow engine, our pick is Dagster. A relatively new tool, Dagster schedules, orders, and monitors computations.
Lastly, Kubeflow and MLFlow serve more niche requirements and are rather related to deploying machine learning models and tracking experiments.
By now, Python has proven itself to be good enough to encourage cloud platform providers to use it for implementing and controlling their services.

Therefore, it is only right that we take a closer look at how Python can be made to run on the cloud. As you might already know, there are three leading cloud providers on the market: AWS, Google Cloud Platform, and Microsoft Azure.
When it comes to computing services, all three providers have services called functions (Lambda, Cloud, and Azure), and all of them support Python. That means we can run almost any Python code in the cloud.
For instance, we can use AWS Lambda Functions to trigger Apache Airflow DAGs once some particular file is added to S3. Alternatively, we could simply run an image resizing code after a photo is uploaded into an S3 bucket, then save it back to S3, and maybe even save some metadata about this event into RDS, such as the AWS relational database system.
Another question you might be asking yourself is, “Can we use Apache Spark in the cloud?”
Yes, we can. All three cloud providers offer us services designed to run and manage big data frameworks, and all of them include Spark.
Furthermore, if you wish to write custom code to create, manage, and work with cloud services, AWS offers a Boto3 library. However, things get a little more complicated with GCP and Azure, as they both have separate libraries for separate services. So, for instance, in Google Cloud Platform, we have to install a separate package to work with BigQuery, Cloudspaner, BigTable, and so on.
Lastly, when it comes to orchestrators, AWS offers a service called managed workflow for Apache Airflow, so we don’t have to manually install the Airflow scheduler and workers. Similarly, GCP has a Cloud Composer, which is also an Apache Airflow.
Azure may not have any Python-based orchestrator, but it is pretty easy to set up Airflow or any other tool of your preference in Azure Virtual Machines.
In simple words, all the big cloud players greatly accommodate Python users in their solutions.
Thank you for reading this article! We hope you found it useful in understanding how Python can help you address the most common data engineering challenges.
If you wish to learn more about Python for data engineering, here are a few resources on our website that are worth checking out:
At STX Next, we’ve been working with Python since 2005, when we first started developing software. That said, we’re always looking to support businesses with tapping into new possibilities using this fantastic programming language.
As part of our vision, we have taken to making data engineering less challenging with Python. So, if you’re interested in learning more about how we can assist you in speeding up your data engineering process to make it more efficient, simply take a look here.
We also offer a wide array of other software engineering services we can provide for you if that’s what you need. And in case you have any doubts or questions, feel free to reach out to us, and we will get back to you as soon as possible!