

Implementing Trunk-Based Development: A Developer's Experience and Insights
Have you ever looked at a development workflow and thought, “There must be a better way to do this”? I know I have. Recently, I held a presentation at STX Next about Trunk-Based Development, and I’d like to share my approach to daily work as a developer. My team and I have spent several months working within the Trunk-Based Development system proposed in this article, and every day, we discover additional benefits of this workflow.
So, how can you benefit from Trunk-Based Development and successfully implement it? To implement trunk-based development, start by managing code changes in small batches and using feature flags to mitigate risks associated with new features. Set up version control systems, establish CI/CD pipelines, and ensure robust testing processes. Read on to find out more.
Understanding Feature Branch Development
Before diving into Trunk-Based Development, let’s review its counterpart: Feature Branch Development, also known as the GitFlow model. In the classical approach to development, a new branch is created for every feature, and it’s maintained until it can be merged back into the mainline. This often results in long-lived feature branches, which can lead to increased complexity and collaboration requirements. Developers may delay integrating their work into the main codebase, potentially resulting in code conflicts and deviations from the stable trunk. During this process, developers often need to check out hotfix branches, resolve merge conflicts, and keep track of multiple branches.
The Feature Branch Development workflow is illustrated below.
.png)
One-Way Ticket to Merge Hell
The example flow above depicts the work of just one developer. Imagine how many branches there would be if a company had 100 developers. What if the number of teams grew to 100?
Continuous merging would become inevitable, often ending in conflicts, commonly referred to as merge hell. Long-lived branches exacerbate this issue, as the longer branches are maintained without merging, the greater the divergence from the main codebase. This leads to complicated merges, increased technical debt, and ultimately, bugs and complicated deployment processes. No one likes merge conflicts; they require focusing on both your code and the conflicting code from another developer.
The Solution: Trunk-Based Development
Trunk-Based Development can rescue you from merge hell, although embracing it can take time. The trunk based development model eliminates feature branches, hotfix branches, or parallel release branches. Developers work on a single branch – known as the Trunk. This strategy enables continuous integration by encouraging a steady influx of code commits into the main branch, reducing integration conflicts, facilitating team collaboration, and improving code stability.
The Four Simple Rules of Trunk-Based Development:
- Single Trunk Branch: Developers directly commit to one branch called the “trunk”.
- Controlled Release Branches: A release manager can create release branches, but no one else can commit to them.
- Frequent Small Commits: Developers commit small changes as often as possible.
- Rigorous Review and Testing: All commits must be reviewed and tested to ensure they do not break the mainline.
The picture below illustrates how developers commit code frequently to the “trunk” branch. Each commit is a small but significant part of the code, such as a single function or method with relevant unit tests (green squares).
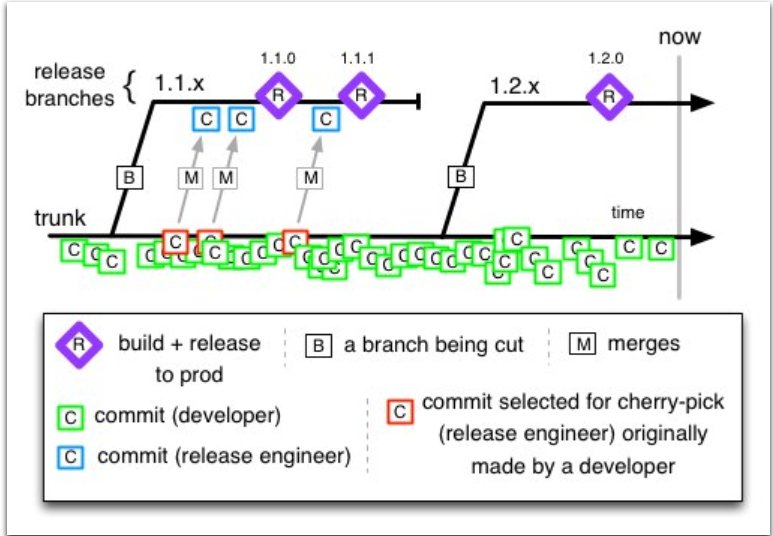
When the trunk branch includes all desired features, a release manager or release engineer creates a release branch. By following these rules, the trunk based development model reduces the risk of merge conflicts and simplifies the development process, making it a preferred approach for many developers.
Typical Developer Activities
In our job, there are several typical cases, such as:
- Planning a new feature
- Creating a new feature
- Fixing a bug in production
- Code review
- Testing
- Merging/resolving conflicts
- Managing code changes
Let’s examine each of these tasks in the context of Trunk-Based Development.
Planning New Features
Planning a new feature is, in my opinion, the most important part of our work as developers. Before starting to code, we should consider how this feature will affect other modules in our system. We need to estimate the complexity of the task and identify the resources required, such as information, knowledge, and testing cases.
During my planning meetings, I always ask:
- Can we split this story/feature into smaller tasks?
- Can this story/feature be developed in parallel by the team?
- What specifics do we need to complete every smaller task in this feature?
Answering these questions helps visualize the code for a specific feature (classes, objects, functions, etc.). This also ensures that all team members understand the upcoming tasks.
Information sharing is crucial for future success and fast code reviews, especially in Trunk-Based Development, where frequent commits are essential. The planning session helps coordinate work, facilitates information sharing, and sets the stage for quick code reviews. Additionally, using tools and methodologies that enable trunk-based development, such as feature flags and CI/CD capabilities, can streamline our Git branching strategy, enhance development efficiency, and minimize risk.
Creating New Features
After planning, our board should be filled with small tasks that define and describe the new features.
In Trunk-Based Development, every piece of code should be well-tested, making it a great opportunity to introduce Test-Driven Development (TDD) into your workflow. The core rule here is to deploy a new commit to the trunk daily. Automated tests play a critical role in this process, ensuring code quality and system stability after every commit. This allows teams to deploy frequently with confidence that new changes do not introduce issues.
This practice helps us in two ways:
- It serves as a symbol of progress.
- It prevents potential merge conflicts.
Imagine a typical developer’s day using the Trunk-Based Development approach. In the morning, the first task is to fetch from the origin/trunk and create a local branch (optional, depending on your Continuous Integration and review process). Next, consider how to create a commit as small and functional as possible.
Remember, no commit should break the mainline (the trunk branch). A release manager should be able to create a release branch from any point in history. Therefore, we don’t deliver unfinished features that may impact users.
I propose two techniques to mitigate such issues: Branch by Abstraction and Feature Flags.
Branch by Abstraction
This technique is extremely useful for component replacement. For example, imagine you have a Memcached instance as a cache manager. Over time, more clients use the cache, increasing complexity (illustrated below).
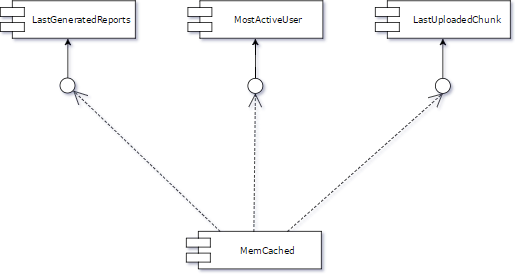
Steps needed for the branch by abstraction:
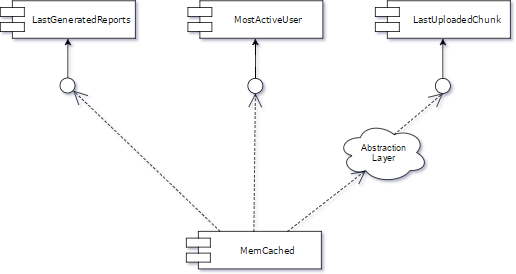
1. Create an Abstraction Layer: Create an abstraction layer between one client (e.g., LastUploadedChunk) and Memcached, ensuring daily commits do not break the trunk.
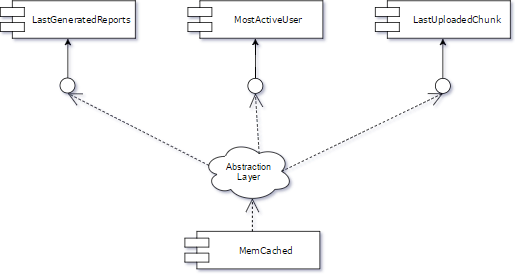
2. Redirect All Clients: Move all clients to the abstraction layer, improving unit test coverage.
3. Develop the New Feature: For one client, develop a new feature using the abstraction layer while maintaining the current functionality for others.
4. Move All Clients to New Component: After development, use the abstraction layer to connect all clients to the new component, such as Redis.
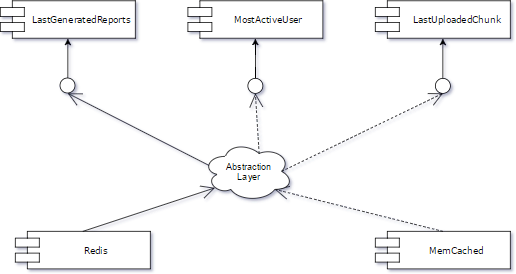
5. Remove Old Components: Delete the obsolete Memcached component and its tests. The abstraction layer can be retained for future use.
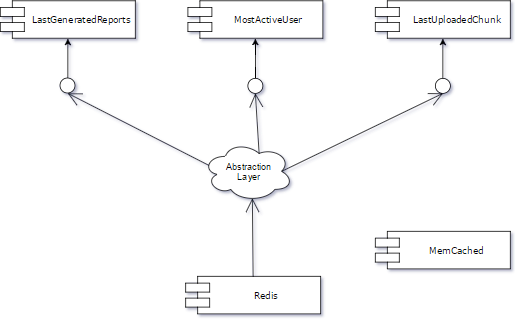
This method allows for seamless replacement of components without breaking the trunk line.
Feature Flags
The second technique often used in Trunk-Based Development is the Feature Flag.
A common argument for Feature Branch Development is that some features require multiple commits over several days, even for a single release. Feature flags help manage this in Trunk-Based Development.
Steps to implement feature flags:
- Create a Flag: Create a unique name for each pending feature in a config file or database.
- Hide Feature: Use the flag to hide the new feature. This can be as simple as an “if” statement or more advanced techniques like decorators or generators in Python.
- Develop the Feature: Continue development with the feature covered by the flag.
- Prepare Release Flags: List flags for the current release.
- Remove Obsolete Flags: After production, remove flags for completed features to avoid future confusion.
The point where we check the feature flag is called a toggle point. Everything controlled by a conditional statement (e.g., an “if” statement) is referred to as a toggle test. There is one primary rule to follow regarding toggle points and feature flags: maintain the minimum number of toggle points necessary to ensure the new feature is properly hidden.
Imagine we are developing a web page that generates reports. There might be various places on the page where weekly reports are displayed. However, if there is only one link redirecting to the reports page, our toggle test should be designed to hide exactly this link. In other words, we should aim to minimize the number of toggle tests associated with a single flag.
The situation is illustrated in the picture below.
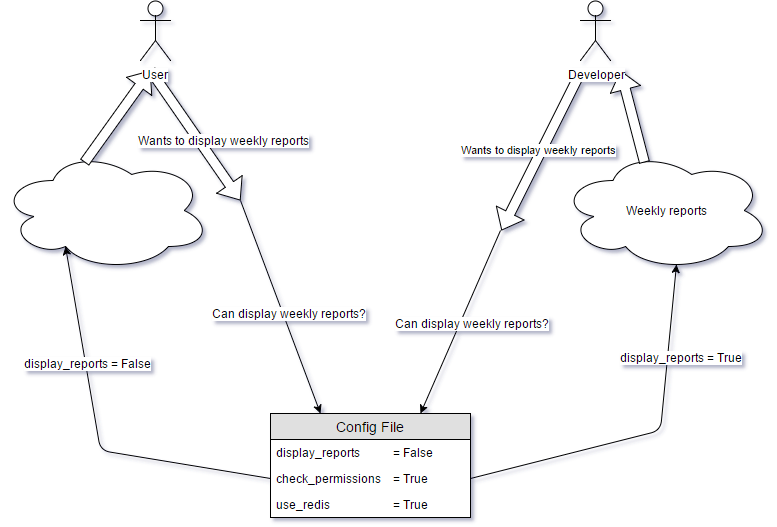
Feature flags streamline development and deployment, ensuring continuous integration without disrupting the mainline.
Fixing Bugs in Production
It happens – bugs can be found even on a release branch. From a developer’s perspective, we cannot commit directly to the release branch. Instead, we locate the bug on the trunk branch and attempt to fix it on the mainline with an additional commit.
Since the mainline and the release branch contain the same or similar code, reproducing any failure from the release branch on the trunk should not be a problem. To ensure code quality, it is crucial to run automated tests against a full staging or production environment. After fixing and committing, we’ll send the commit ID to the release manager, who will cherry-pick it to the release branch (we’ll discuss this more in the following section).
Code Review
As Cory House once said, "Code is like humor. When you have to explain it, it's bad". Following this principle, the best way to judge your code's clarity is through a code review (or peer review).
Remember, in Trunk-Based Development, we make small commits with only one function or method, and plan all features together with the team. This means code reviews will be straightforward. The feature has already been well-described, and a plan has been established. Every day, the team will produce a few small commits that need review.
You might think this sounds tedious, but in practice, it's quick and efficient – reviewing just one function and its tests. And since you're already familiar with the context of all features from the planning sessions, you'll primarily focus on the technical aspects of the code.
As a reviewer, you will spend a maximum of 15 minutes a day on reviews.
Testing
Testing in Trunk-Based Development is pretty straightforward. We must cover our features with tests.
There are two main types of tests:
- Unit Tests: These cover newly created methods or functions. Unit tests should focus only on the tested function, with other functions being stubs or mocks.
- Integration Tests: These cover the integration process, ensuring that code using functions from separate modules works as expected.
From a tester's perspective, feature flags allow us to toggle features on and off easily. This is an excellent opportunity to introduce A/B testing in our company.
Merging & Resolving Conflicts
With only one branch, merging is not required, eliminating merge conflicts – one of the significant benefits of Trunk-Based Development. Additionally, using short-lived branches allows developers to make small, frequent updates to the main branch, simplifying the merging process and facilitating continuous integration and delivery.
Responsibilities of the Release Manager
The release manager has a specific role in Trunk-Based Development. This individual is the only one allowed to create release branches and fix bugs in production. Managing long-lived branches is crucial as they can lead to issues like 'merge hell' and increased technical debt due to complicated merges. The release manager must ensure that branches do not diverge significantly from the main codebase to prevent bugs and complicated deployment processes.
They have two primary responsibilities:
- Creating a new release branch
- Cherry-picking any necessary hotfixes
Creating a New Release...
…branch.
I intentionally omitted the word “branch” from the subheading because the approach depends on release frequency:
- Infrequent Releases: For companies rarely delivering new features (once a month or less), the release manager should create a release branch for each minor version. Keeping one release branch alive for a long time ensures clients don’t have to wait too long for fixes. However, be cautious of long lived branches, as they can lead to challenges like 'merge hell' and increased technical debt. This allows for easy version updates with cherry-picked hotfixes. See the illustration below.
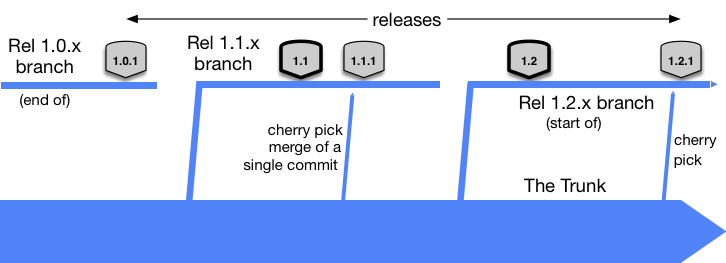
- Frequent Releases: Teams with high release frequency do not need release branches. They can use the trunk to perform releases, using commit IDs or timestamps as versions. Version control mechanisms like tags can further streamline this process. Bugs are addressed on the trunk as normal features, enabling quick releases. See the example flow below.

Cherry-Picking Hotfixes
One of the core principles of Trunk-Based Development is committing directly to the mainline. When a bug is found in a release, changes should not be made directly to the release branch. Instead, reproduce the bug on the trunk, fix it on the main branch, and then the release manager can cherry-pick the commit into the release.
Committing directly to the release branch and then merging to the trunk reintroduces merge conflicts and could lead to regressions in subsequent releases – contradicting the advantages of Trunk-Based Development.
Why Trunk-Based Development is a Game-Changer
Trunk-Based Development is not a new concept but has gained popularity recently. With major IT companies adopting this trunk-based development model, now is a great time to introduce it into your organization.
Benefits of Trunk-Based Development:
- It eliminates merge conflicts.
- It supports best practices, including feature planning, small commits, and writing backward-compatible code.
- It speeds up the deployment of new features compared to feature branching.
- In the long run, small commits can help decompose a monolithic application into manageable services.
Personally, I can’t imagine going back to traditional methods.
If you’d like to learn more about Trunk-Based Development, explore the bibliography for further reading. We’re also happy to answer any questions here.
For more articles, don’t forget to subscribe to our newsletter below.
Sources
- Trunk-Based Development
- What is Trunk-Based Development?
- Enabling Trunk-Based Development with Deployment Pipelines
- Branch By Abstraction
- Branch By Abstraction by Martin Fowler
- Feature Flags
- Feature Toggles by Martin Fowler
- Feature Flags by Pete Hodgson
- 11 Proven Practices for Peer Review
- Semantic Versioning






