

Introduction
Everyone (I hope), who is working with data knows how important it is to test your models’ logic and data thoroughly. Good tests will not only save you time and money (either company’s or yours) in the future. They will also increase your confidence over your work.
In dbt we can implement a few different types of tests. Probably well known to everyone who worked a little bit with dbt - data tests. Under those we can put generic, singular and source freshness tests. dbt has a bunch of build-in data tests, but we can easily extend those with packages available on dbt’s Package hub. Next to data tests, in version 1.5 and higher of dbt Core we can define contracts for our models which we can treat as - schema tests. Moreover, from version 1.8 dbt introduce unit tests - which we can use to test our SQL models’ logic against predefined data.
As you can see there are many possible tests we can implement in data engineering projects.
Before you start writing different kinds of tests in your own projects, please remember that not all features might be available in the database/data warehouse of your choosing. The place where you could possibly find information about supported or not supported features could be placed in a specific data platform’s adapter description: trusted adapters, community adapters.
Ok, let’s take a deeper dive into the world of dbt tests.
In my examples I will use data generated with Jaffle Shop Generator. It is a free and easy to use generator for data engineering projects, that will allow me to present you with more real-life examples. As my data warehouse I will use the Postgres database.
Data tests
Source freshness test
Despite the fact that source freshness checks are not strictly tests, I decided to include them in this article. Lets say I want to check if the data about tweets that my EL job is ingesting into the warehouse is up to date. I can do it by adding a freshness block to the tweets source defined in sources.yml file. Inside of it I can define two thresholds: warn_after or error_after. For both of them I can define time in minutes/hours/days after which dbt will show a warning or error message. One more important (but not mandatory in some cases, about which I will write later) thing to have inside the table is a column which will be treated as a freshness marker. When you have such a column you can point to it by defining the loaded_at_field property. In the example below I showed possible use cases for such tests. I defined both thresholds high to get only the warning message because dates in the tweeted_at column generated with the jaffle shop generator were pretty old.
1# sources.yml
2version: 2
3
4sources:
5 - name: jaffle_shop
6 database: jaffle_shop
7 schema: raw
8
9 tables:
10 - name: tweets
11 identifier: raw_tweets
12 freshness:
13 warn_after: {count: 365, period: day}
14 error_after: {count: 470, period: day}
15 loaded_at_field: tweeted_atLike I mentioned before, loaded_at_field is not always necessary since dbt is able to get such information from warehouse metadata. It is not available for all warehouses so better check documentation for supported ones (docs)
Ok, we defined freshness but how to check it? It is really simple just run command:
1 dbt source freshness
For me it returned a warning since my data is older than 365 days but not older than 470 days.
11 of 1 START freshness of jaffle_shop.tweets ................................... [RUN]
21 of 1 WARN freshness of jaffle_shop.tweets .................................... [WARN in 0.06s]
Freshness tests are really nicely built into dbt Cloud where you can define jobs to run freshness before running models, and in case of the stale data you can stop the whole job from running. When it comes to dbt Core you can build your own custom-made solution which will read target/source.json where source freshness data is stored, and take proper actions based on that. You can also use elementary packages to visualize freshness tests results and send alerts when thresholds are crossed - docs.
Generic tests
Build-in
dbt has four built-in generic tests that you can use straight away on your models, sources, seeds and snapshots. Those are:
uniquenot_nullaccepted_valuesrelationships
Those data tests names are pretty self explanatory (maybe except relationships), but nonetheless let me put them in use, and explain in more detail. Since I can use data tests on sources as well, I will extend my previous example.
1# models/sources.yml
2version: 2
3
4sources:
5 - name: jaffle_shop
6 database: jaffle_shop
7 schema: raw
8
9 tables:
10 - name: products
11 description: Contains data about products served by shops.
12 identifier: raw_products
13 columns:
14 - name: sku
15 data_tests:
16 - not_null
17 - unique
18 - name: type
19 data_tests:
20 - accepted_values:
21 values: ['jaffle', 'beverage']
22 - name: supplies
23 description: Contains data about supplies used to create the products.
24 identifier: raw_supplies
25 columns:
26 - name: id
27 data_tests:
28 - not_null
29 - name: sku
30 data_tests:
31 - not_null
32 - relationships:
33 to: source('jaffle_shop', 'products')
34 field: sku
35 - name: tweets
36 identifier: raw_tweets
37 freshness:
38 warn_after: {count: 365, period: day}
39 error_after: {count: 470, period: day}
40 loaded_at_field: tweeted_at
I introduced two new tables in jaffle_shop source: products and supplies. I added a column block with name property and data_tests block in each table.
In some places you can still see people using a tests block instead of data_tests. It is because in version 1.8 dbt added unit tests with new block unit_tests. To introduce more consistency they added data_tests alias for tests block.
Inside the mentioned data_tests block you can define tests you want to run. This block can be defined on the table or column level. In my example I defined it on column level so my tests will be run on these specific columns. On the column sku in the products table I used a not_null test that checks if there are no null values and a unique test to validate that there are no duplicated values in this column. It is common to use such test combinations on primary-key-like columns. Next, on column type I used the accepted_values test. It validates if values present in it are only the ones of the values defined in values property list. It makes sense to use such a test when you expect only the certain values in a column and any change in those may affect your downstream logic or assumptions. The last type of build-in test: relationships I used in table supplies. It checks if each sku code in supplies exists in the products table. It makes sense to use it when you want to check if the relationship between two columns still exists.
From external packages
Like I mentioned before there are dbt packages that extend the number of data tests available for the user right away. Two of which I will present to you in this article are:
(If you don’t know how to install packages in dbt please check the links above, they will guide you.)
When it comes to using external packages check if according to the publisher your db/dwh is supported. dbt-expectations publish such lists in package description. Please remember that some dbs/dwhs are based on others and despite not being on the list they might be at least partially supported, eg. AWS Athena is based on Trino and Presto. Since Trino is supported by dbt-expectations you can use this package with AWS Athena.
In both packages there are plenty of useful tests. I will not describe them all since it is not a goal of this article. But I would like to present to you, a couple of maybe less obvious tests.
Testing freshness of models
I hope you remember the dbt build-in source freshness test. It has two downsides: you must run a separate command to check it and it can only be used on sources. But there might be times when you want to check if your data is fresh in e.g. staging models. With help comes both dbt-utils and dbt-expectations packages. In the first one test is called recency, where in the second one we have two options expect_row_values_to_have_recent_data and expect_grouped_row_values_to_have_recent_data. In basic usage both give the same functionality. dbt-utils’ recency test can use optional group by column parameter where in dbt-expectations’ test you have separate tests for that. Both of the dbt-expectations tests also have optional data filter parameters. In my example I used the dbt-utils test.
Since it should be used on models I created a staging model for tweets data:
1# models/staging/stg_jaffle_shop_tweets.sql
2with
3 source as (
4 select * from {{ source("jaffle_shop", "tweets") }}
5 ),
6 renamed as (
7 select id as tweet_id, user_id, tweeted_at, content
8 )
9
10select *
11from renamed
I added yml file for it, where I configured data recency test:
1# models/staging/stg_jaffle_shop_tweets.yml
2version: 2
3
4models:
5 - name: stg_jaffle_shop_tweets
6 description: This model contains tweets data about jaffle shop
7 data_tests:
8 - dbt_utils.recency:
9 datepart: day
10 field: created_at
11 interval: 470
The principle is basically the same as in source freshness tests, this test will start failing when data in the created_at column will be older than 470 days. The thing that distinguishes source freshness tests, and tests mentioned above is inability to set warning levels in latter ones.
Testing model’s cardinality
During my work with the jaffle shop data, I decided it would be nice to calculate how big a margin each product has. To do so I created two staging models one for products and another one for supplies. Based on them, intermediate model where I calculated margin like so:
1# models/intermediate/finance/int_products_intergredients_cost.sql
2with
3 supplies as (
4 select supply_sku, cost, product_sku
5 from {{ ref("stg_jaffle_shop__supplies") }}
6 ),
7 supplies_per_product as (
8 select product_sku, sum(cost) as product_cost
9 from supplies
10 group by product_sku
11 )
12
13select
14 products.product_sku,
15 product_name,
16 price,
17 supplies_per_product.product_cost
18from {{ ref("stg_jaffle_shop__products") }} as products
19left join
20 supplies_per_product
21 on products.product_sku
22 = supplies_per_product.product_sku
The join I used there and the whole logic is not complicated, but even so I decided that it would be nice to check that my intermediate model contains all products. To do so I can use one of db_utils tests called cardinality_equality, it checks if the number of each unique value in both columns is the same.
In my case implementation looks like this:
1# models/intermediate/finance/int_products_intergredients_cost.yml
2version: 2
3
4models:
5 - name: int_products_ingredients_cost
6 columns:
7 - name: product_sku
8 data_tests:
9 - dbt_utils.cardinality_equality:
10 field: product_sku
11 to: ref('stg_jaffle_shop__products')
Testing multi-column primary key
Not all tables have one column which we can treat as the primary key. In the jaffle shop this kind of table is the one containing data about supplies used for certain products (table: supplies). It has supply’s sku that is not unique because the same supply can be used in different products, but combination of supply’s and product’s sku should be unique. We can test that, and prevent ourselves from problems in the future. Both packages have tests for this kind of job. db_utils has a unique_combination_of_columns test where dbt_expectations has expect_compound_columns_to_be_unique. The second one comes with optional parameters like, data filtering and ignoring, which might be useful in some use cases. I used the latter one. Here is example usage on the supplies staging model:
1# models/staging/stg_jaffle_shop__supplies.yml
2version: 2
3
4models:
5 - name: stg_jaffle_shop__supplies
6 data_tests:
7 - dbt_expectations.expect_compound_columns_to_be_unique:
8 column_list: [ "supply_sku", "product_sku" ]
9 ignore_row_if: "any_value_is_missing"
10 quote_columns: false
The ignore_row_if property set to any_value_is_missing value means that rows where supply_sku or product_sku are null will be excluded from the test. The purpose of quote_columns is the same as the one for seeds in dbt - docs.
Custom
Let's assume that you didn’t find tests that you need, neither in build-in ones, nor in the ones from external packages. Don’t worry, your case might be very unique, and for that you can always write your own custom tests. The best place to put your custom generic tests files inside the dbt project is tests/generic/ directory. You can also store them in the macros folder, but in my opinion the first option is better since it makes things more intuitive, and self explanatory. Let say it is important to you, to be sure that values inside the sku column, will always follow the same pattern. We can create a test that will check it. It could looks something like this:
1# tests/generic/test_values_match_regex
2{% test values_match_regex(model, column_name, pattern) %}
3 with
4 validation as (
5 select {{ column_name }} as test_column
6 from {{ model }}
7 ),
8 validation_errors as (
9 select test_column
10 from validation
11 where test_column !~ '{{ pattern }}'
12 )
13
14 select *
15 from validation_errors
16
17{% endtest %}
Applying a custom test is as simple as the built-in ones. I added it to sku column in products table:
1 - name: products
2 identifier: raw_products
3 columns:
4 - name: sku
5 data_tests:
6 - not_null
7 - unique
8 - values_match_regex:
9 pattern: '^[A-Za-z]{3}-[0-9]{3}$'
From now on each value in the sku column will be checked against the pattern: start with three characters followed by a dash and end with three numbers.
There is one important thing to keep in mind when writing your own tests. Your SQL query must be written to find rows that do not comply with your assert. That is why I used !~ in my query, to find values that do not match the pattern I want to “enforce” on columns.
When it comes to generic tests you can also overwrite build-in ones and also configure your tests to only return warnings when they fail.
Singular
Singular tests are less flexible than generic ones. They come in handy when you have a specific situation that applies only to one table/column, which you will probably not use anywhere else. For example you want to check that the sum of subtotal and tax_paid is equal to order_total in the orders table. In that case you can write a singular test to validate it:
1# tests/assert_subtotal_and_tax_is_equal_to_order_total.sql
2with
3 validation as (
4 select subtotal + tax_paid as total, order_total
5 from {{ source("jaffle_shop", "orders") }}
6 ),
7 validation_errors as (
8 select total, order_total
9 from validation
10 where order_total != total
11 )
12
13select *
14from validation_errors
Model contracts
Data tests are great, but they have one downside mentioned earlier. They can only be run after a proper model was built, and it is hard to ensure that only agreed columns with correct data type are present.
Just want to mention that dbt_expectations packages has expect_column_to_exist but you have to remember to add it to each column, it doesn’t validate data type and of course it will run after model build.
With help comes contract tests introduced in dbt v.1.5. They are a great way to enforce consistent schema and apply constraints on models. When you define such a contract, each time you build your model, dbt will run pre-check and if there are any differences, the model will not be built, and you will be informed why.
One thing to remember, dbt don’t check data type’s details like size, precision or scale, nonetheless you should put it in your data types otherwise dbt will use default values.
Second thing to remember, supported constraints differ from warehouse to warehouse. Please, check dbt’s docs before using one.
To make an example I have created a mart model called fct_products_margin. It contains information about the gross margin of each of your products. Let say some BI tool is using it and I must ensure that schema and data types will not change unnoticed. Otherwise it may crash important tables or diagrams. To start using contract on model I must add a couple of things to the its yml file:
configblock withcontractblock and insideenforcedproperty set totruecolumnsblock withnameanddata_typeproperty for every column, and optionallyconstraints
1# models/
2version: 2
3
4models:
5 - name: fct_products_margin
6 config:
7 contract:
8 enforced: true
9 columns:
10 - name: sku
11 data_type: string
12 constraints:
13 - type: not_null
14 - type: unique
15 - name: name
16 data_type: string
17 - name: price
18 data_type: int
19 - name: gross_margin
20 data_type: int
21 - name: gross_margin_percent
22 data_type: decimal(5,2)
When e.g. price column name would change to product_price where in the contract it is still price, dbt during dbt run would return an error:
1Compilation Error in model fct_products_margin (models/marts/finance/fct_products_margin.sql)
2This model has an enforced contract that failed.
3Please ensure the name, data_type, and number of columns in your contract match the columns in your model's definition.
4
5 | column_name | definition_type | contract_type | mismatch_reason |
6 | ------------- | --------------- | ------------- | --------------------- |
7 | price | | INTEGER | missing in definition |
8 | product_price | INTEGER | | missing in contract |
9
Last thing to remember. Contract will not run during dbt test command.
Unit tests
If, like me, you are a person that came to the data engineering world being earlier at software engineering, you know for sure how important unit tests are. When it comes to data engineering projects unit tests are usually not so popular, but in my opinion they should be! They are a great way to test specific aspects of models like complex case expressions, regular expressions, window functions before they will hit production. You will be able to test edge cases that currently may even not be present in your real life data.
Ok, so since unit tests are so valuable the question is how hard is it to write such tests in dbt. In my opinion it is fairly easy. All you need to do is define input data for your model and expected output. Let's dive into some examples. In stg_jaffle_shop__customers model I find out that some names in customer_name column contains various prefixes and suffixes like Mr., Mrs, PhD, I decided to add one more column named cleaned_customer_name that should contain names without such prefixes and suffixes. Here is my model:
1# models/staging/stg_jaffle_shop__customers.sql
2with
3 source as (
4 select *
5 from {{ source("jaffle_shop", "customers") }}
6 ),
7 renamed as (
8 select id as customer_id, name as customer_name
9 from source
10 ),
11 cleaned_names as (
12 select
13 *,
14 regexp_replace(
15 customer_name,
16 '^(Mr\.|Mrs\.|Miss|Dr\.\s*) | (\s*MD|PhD|DDS)$',
17 '',
18 'i'
19 ) as cleaned_customer_name
20 from renamed
21 )
22
23select *
24from cleaned_names
It makes sense to test the regex expression to be sure that it is constructed correctly. To do so we need to create a new yml file that will contain unit tests for this model. This yml file must be placed somewhere inside the models directory. I created folder unit_tests inside models/staging where I will put all yml files for staging. The name of the file doesn’t matter for dbt. I named it the same as the model: stg_jaffle_shop__customers.yml. When it comes to the naming of specific tests I usually prefix it with test_, but you can come up with your own naming convention, just remember to follow it throughout your project.
1# models/staging/unit_tests/stg_jaffle_shop__customers.yml
2unit_tests:
3 - name: test_cleaned_customer_name
4 description: "Test if regular expresion clean names from redundant prefixes and suffixes"
5 model: stg_jaffle_shop__customers
6 given:
7 - input: source('jaffle_shop', 'customers')
8 rows:
9 - {name: Adam Smith }
10 - {name: Mr. Nicole Whitney }
11 - {name: Mrs. Glenna Torres }
12 - {name: Rob Rivera MD }
13 - {name: Elena Holden Phd }
14 expect:
15 rows:
16 - {cleaned_customer_name: Adam Smith }
17 - {cleaned_customer_name: Nicole Whitney }
18 - {cleaned_customer_name: Glenna Torres }
19 - {cleaned_customer_name: Rob Rivera }
20 - {cleaned_customer_name: Elena Holden }
You can see there are a couple of things that have to be set. name it is the name of the test, model must point to the model name that we want to test with our test. given block must contain all the models/sources your model relies on directly. In my example stg_jaffle_shop__customers rely only on one source. For each of those models/sources you must define dummy data you want to run your test with. expect block must contain data you expect your model to return. In my example I used dummy data defined as a dict inside a yml file, but you can use csv or sql as well. What is important is that you don’t need to define all the columns for your given and expect rows when you use dict or csv format. Inside the unit_tests block you can define multiple test cases, but in my opinion they all should test the same model, for the sake of readability.
To run unit tests you can use dbt build or dbt test command. During my work on stg_jaffle_shop__customers model I ran mentioned above test and it actually failed:
1actual differs from expected:
2
3@@ ,cleaned_customer_name
4 ,Adam Smith
5+++,Elena Holden Phd
6---,Elena Holden
7 ,Glenna Torres
8 ,Nicole Whitney
9+++,Rob Rivera MD
10---,Rob Rivera
This output gave me valuable information that something is wrong with my regex when it comes to suffix removal. I fixed it and my test started passing, making me much more confident about the transformation I wrote.
By default unit tests will run for all versions of your models. So if you want to define different unit tests for different versions of your model, you can change it by specifying proper configuration inside test’s yml file (more information in docs). Another important thing is that like in Python’s unit tests you can also mock/overwrite macros/functions and environment variables, it is very important when you want to isolate your unit test.
How to run tests
Ok, so we wrote our tests, they are useless until we start running them. To run all tests (both data and unit) you can simply use:
1dbt tests
You can also specify --select flag and run only a subset of tests e.g. data tests, only generic tests or even tests for specific source/model. For more information about the select flag please check out dbt docs.
When it comes to running tests on production using first dbt run and then dbt tests is not always the best option. Why? Because you will test all models after they are built. In that case you will not be able to stop the process if some e.g. source or staging test failed, meaning that there is something wrong with your logic or data. Much better option is to run:
1dbt build --exclude-resource-type unit_test
This command will run models and associated with its tests in DAG order. By default it will skip running downstream models if some tests in upstream failed. Also, it will not run unit tests about which I mentioned before in Blog post - Testing in dbt. It is a good practice to run unit tests only in development and CI environments. It is because code landing on production should have already been tested during the development and deployment process, and there should be no need to waste time and resources, to run those tests again on production.
Keep in mind that running dbt build will also build dependencies and seeds and that might take some time. If you will have to run your models quite often, like every couple of minutes you might want to skip it as well.
Test results observability
When it comes to real-life projects you will probably run your tests on some schedule. How often? It will depend on the project's requirements, but either it will be once a day or a couple of times per day, you will need some place to check the health of your transformations. Of course you can check output generated by dbt commands but it will not be handy in bigger project. You can also build your own system, that will take dbt’s artifact and generate reports, but if you don’t need custom-made system better use elementary. It is a great tool, build to monitor your dbt projects. It comes both as paid cloud platform and open-source software package. Since it is made as dbt package installation process and integration within you project is really easy. Of course free version is stripped of many functionalities and integrations, but it is still able to generate valuable dashboard with tests results and give you ability to set up notifications/alerts to Slack and Teams when something is wrong with your data.
When it comes to installation and setting elementary up everything is nicely described in docs. When elementary is installed correctly you should be able to generate local html report with:
1 edr report
When this command finish running, you will see in web browser report similar to this one:
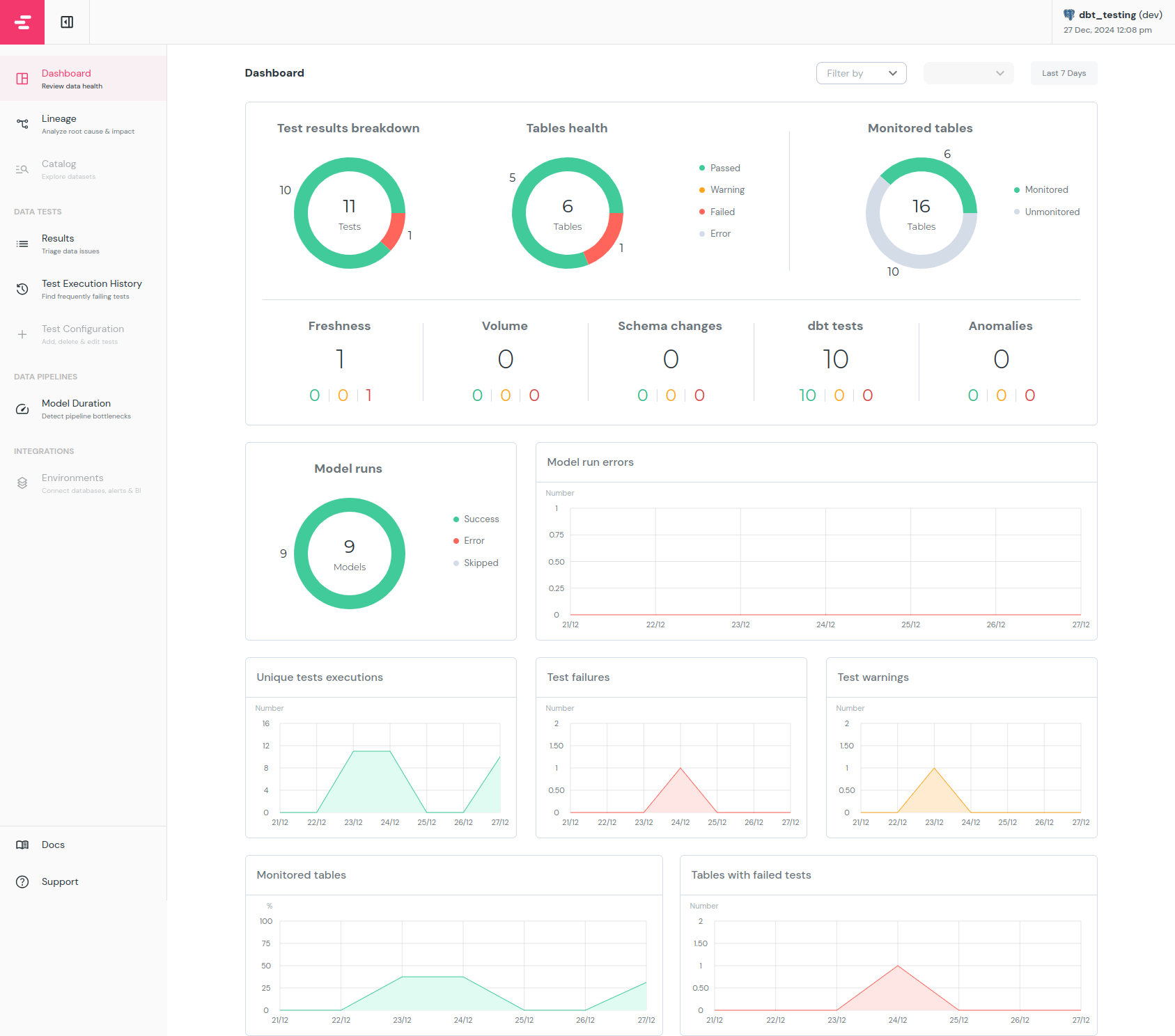
As you can see, the report shows both current tests status as well as history. You can also go into Results and Test Execution History(left panel) and check more information about each test. There you will find which and when the test failed, how long it takes to run each test and many more. By default elementary will not gather data about source freshness. To do so it needs a little bit more configuration, check docs for more information.
What is important is that elementary works on dbt’s artifact files so before generating a report you must run dbt test and dbt source freshness commands, otherwise it will show no data at all (if you didn’t run tests for your project before) or outdated data.
In the production environment there is no use for a report generated locally, fortunately elementary comes with command: edr send-report. It will generate the report and send it to e.g AWS S3 (docs). This way you can easily configure S3 bucket to serve this report as a website. It may be available to you and others who should have access to it.
The process of setting up Slack and Teams alerts is very well documented in elementary docs (link). In general what is worth mentioning is that you can set up such alerts for tests failures or warnings, model runs failures, and on source freshness failures. Beside basic configuration, elementary can also use meta data field like owner, subscribers, tags in your models and tests to mention only specified users or group in the Slack message. In bigger projects it makes much more sense to utilize it so you don’t have to check every single one alert, only those to the models you are responsible for.
Summary
I hope this article showed that in dbt right now we have a broad spectrum of features and tools ready to test different aspects of data and transformations. To sum up we have:
- source freshness tests - they will inform if source data became stale
- generic and singular data tests - build to test data stored in your models. You can both create your own tests or use packages like
dbt-utilsanddbt-expectationswith many tests ready to use - model contracts - made to enforce model constraints, column names and data types for important models
- unit tests - great to tests complex transformations with dummy data in your local and CI environment
There are also tools like elementary-data great to improve observability and monitoring over your data and tests.






