

How to make predictive maintenance work in factories
I’ve spent years working with factories that want to prevent failures before they happen. And I’ve learned that most don’t struggle with the algorithms, but people, process, and reality on the shop floor.
Predictive maintenance looks simple on a slide, but in practice, it forces you to rethink how decisions are made, how data is collected, and who actually trusts the system. I’ve seen projects succeed, and I’ve watched others die on day one – not because the math was wrong, but because the approach was.
In this article, I’ll share a practical, proven implementation roadmap to help predictive maintenance projects in manufacturing succeed instead of stall.
Business benefits of predictive maintenance in manufacturing
When predictive maintenance works, the effects are visible almost immediately: not in dashboards, but on the factory floor. The most compelling reasons to invest show up in how operations run when failures stop being a surprise.
Downtime reduction
Unplanned downtime is the most expensive kind of silence on a factory floor. Predictive maintenance in manufacturing breaks the cycle of failure-repair-failure by spotting early signals of wear and letting teams act before a breakdown stops production. Sensor data and machine insights turn maintenance into a scheduled activity instead of an emergency response.
You can observe the payoff quickly. Lines run longer without interruption, and parts are replaced when they actually need attention, not because a calendar said so. Equipment lasts longer, service costs drop and the factory gains stability instead of living at the edge of its next failure.
Asset life extension
Machines leave clues long before they fail – temperature shifts, vibration patterns, pressure fluctuations. These signals reveal wear early, as long as someone is watching. With continuous monitoring, maintenance teams can act while an issue is still small, instead of waiting for a breakdown that destroys parts, schedules and budgets. Digital twins make this even easier by giving engineers a live view of equipment behavior, no matter where they are.
Extending asset life goes beyond an operational win, it’s also a financial one. Spare parts erode budgets fast as systems age. Honeywell estimates that a $10 million distribution system might start with around $200,000 in spare parts. In the first two years, that cost sits at a manageable level. By year six, the annual spare-parts budget can climb to roughly 25 percent of the initial inventory value, or about $50,000. Aging equipment becomes more expensive equipment, unless the failures that drive those costs are prevented.
Lower costs
One of the clearest benefits of predictive maintenance is cutting costs, and the numbers truly put it in perspective. An Industry Week & Emerson study found that unplanned downtime costs industries around $50 billion a year, and equipment failure accounts for 42% of that.
In predictive maintenance, instead of waiting for something to break (run-to-failure) or replacing parts too early just to be safe (preventive maintenance), we use sensor data and analytics to service equipment only when it’s actually needed. Predictive models spot early signs of wear or malfunction, letting teams act before problems escalate.
In practice, this means fewer unplanned stops, less wasted downtime, and avoiding unnecessary part replacements. The machine gets serviced at the right moment, the production line keeps running smoothly, and costs go down. All because the decisions are guided by data rather than guesswork.
Safety
Equipment failure is costly, but it’s also a leading cause of injuries and fatalities in industrial settings. With predictive maintenance, you can monitor equipment in real time using sensors and IoT technologies. The system picks up even subtle deviations, and predictive models flag potential failures before they turn into dangerous situations. This means maintenance can be scheduled proactively, avoiding conditions that could put people at risk.
Potential challenges
Hardware or software issues
From my observations, many companies struggle with the quirks of existing systems and data when implementing predictive maintenance. Sometimes devices aren’t built to integrate easily with IoT sensors, or legacy software makes it hard to collect consistent information.
For example, modern sensors can stream data continuously, but older equipment often can’t signal events in real time. That makes it tricky to know exactly when something goes wrong. On top of that, different systems store data in different ways – one might use a 1-10 rating, another 1-5, a third separates “device performance” from “weather,” and yet another just has a single comment field. Some systems update hourly, others every five minutes. Do you wait for the slower system, or act on the faster one?
I believe that the right approach depends on the business context. Understanding the operational environment – knowing which signals matter and how to interpret them – is just as important as the technology itself. That domain knowledge often makes the difference between a predictive model that works and one that doesn’t.
ROI proof
Predictive maintenance demands upfront spending, while returns arrive later, which makes some organizations hesitate. Weak data compounds the problem as plants already lose money because their data is unreliable, yet improving it is mandatory before any model can work.
Complex systems add another layer. Advanced assets need customized models that evolve over time, and each refinement requires more data and budget. On the technical side, running models at the edge limits computing power, so teams compress them to keep accuracy without slowing production.
Significant ROI is achievable, but only when leaders accept that value grows in stages, not in the first week.
Change management
Most companies are obsessed about ROI, but it doesn’t matter if the people on the floor refuse to use the system. Veteran engineers rely on instinct built over decades, and one false alert is enough for them to write off a predictive model entirely – I have seen this happen.
Technology can be just as stubborn. Some machines were never designed for sensors, and in extreme environments – like high-temperature boilers – instrumentation simply can’t survive. Retrofitting becomes a battle with physics, not process.
Then comes the human reality. We audited an oil and gas project where a vendor proudly delivered a sleek tablet app. Charts, prompts, everything polished. It failed on day one because operators wore thick gloves and couldn’t use a touch screen. The old setup with big physical buttons worked for a reason and a solution that ignores the user is not a solution at all.
Implementation roadmap
My background is rooted in engineering and that shapes how I look at predictive maintenance projects. Many companies approach them as an IT exercise; they start with tools and algorithms instead of beginning with the process. In manufacturing that approach backfires, because predictive maintenance is closer to a Six Sigma effort than a software rollout.
Six Sigma gives a structure for improving a process – define, measure, analyze, improve and control. In many factories the mistake happens at the very beginning. Teams jump straight to “improve” and treat predictive maintenance as the plan instead of the outcome. They assume the solution before they’ve proven the problem.
A better path is to run the full cycle. First define what hurts: recurring failures, wasted technician hours, long changeovers or service interruptions. Then measure the real impact of those issues – not impressions or anecdotes, but data.
Only then does the analysis stage have meaning. Sometimes the right fix is a predictive maintenance model, sometimes it’s something simpler, like better visualization for operators or tighter maintenance scheduling. Predictive maintenance should be a conclusion from the analysis, not a starting point.
If the model is in fact the right direction, it belongs in the improve phase as a project output. The control phase closes the loop, you check the results against the original measurements to see whether the change worked. Did time between failures increase? Did the number of interventions drop? Did service hours go down? Predictive maintenance has value only when the process proves it. So, let’s now take a closer look at the implementation roadmap.
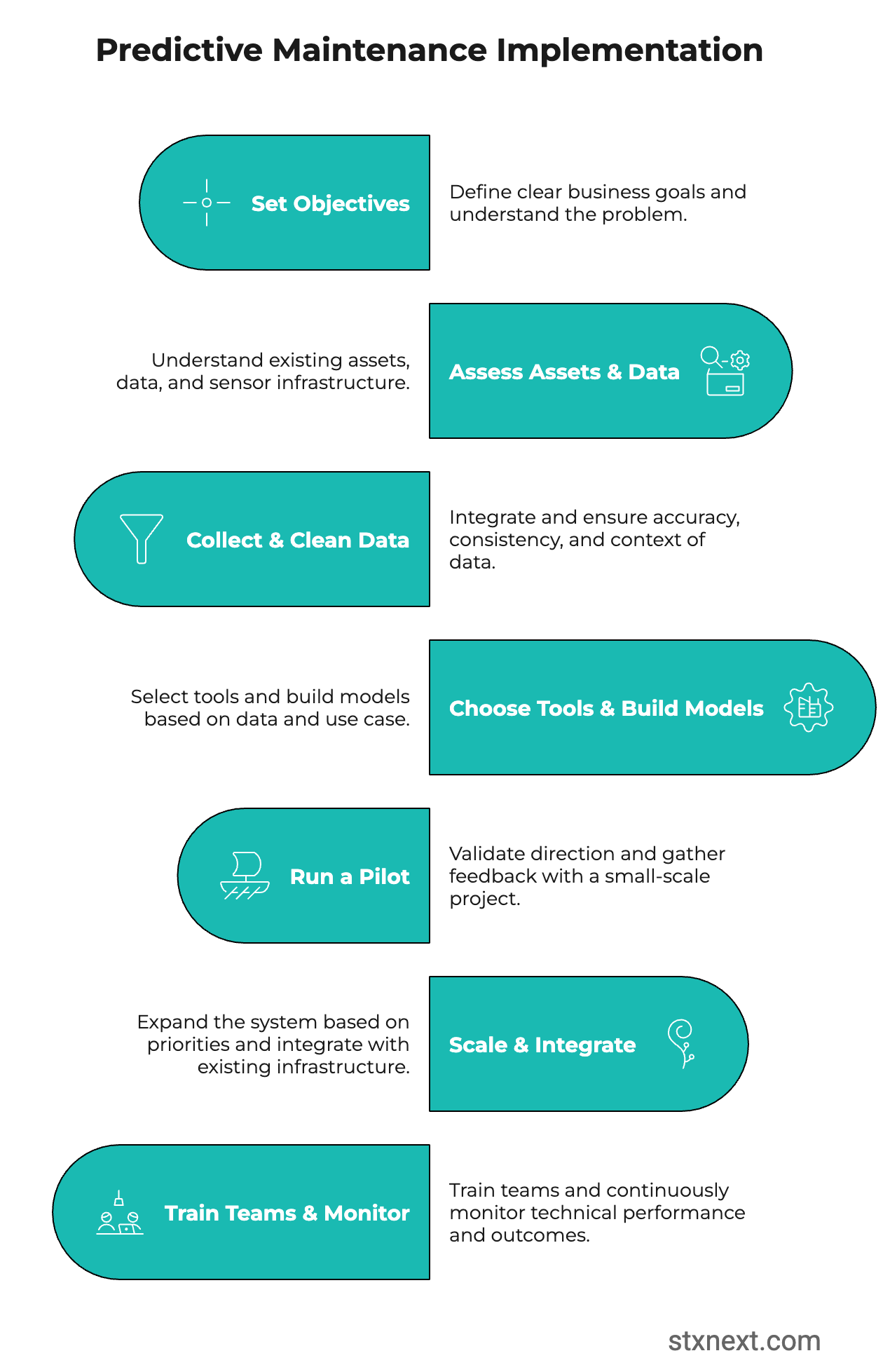
Step 1: Set objectives
Every predictive maintenance initiative should start with a clear business objective. The ultimate goal is always the same, i.e., to reduce costs or improve efficiency. But getting there requires a precise understanding of what problem we’re actually solving.
That’s why I always stress that these initiatives shouldn’t be driven from management only. The best ideas often come from the floor – from engineers, operators, or maintenance specialists who know exactly where the real inefficiencies are.
In manufacturing, this stage takes on a specific flavor because of the nature of the data. We’re talking about tens or even hundreds of millions of IoT records every day, streaming in real time from sensors measuring temperature, vibration, or pressure. The volume and velocity of the data make setting the right goals and designing the right infrastructure critical.
At the highest level, objectives, KPIs, and ROI expectations should all tie back to a tangible business outcome that makes a measurable difference.
Step 2: Assess assets & data
The next step is to understand what data your company already has. Which assets are most critical and what kind of data or sensor infrastructure do you already have in place? This helps the team responsible for the implementation understand how solid the foundation already is, and where the biggest risks and opportunities might lie.
It’s also extremely important to weigh the cost of instrumentation against the potential benefits. In my experience, not every machine needs a full set of sensors. The value depends on how much predictive insight can actually improve performance or reduce downtime.
For example, in one project I worked on, we monitored machines where certain parts naturally wore out over time. By predicting when a component would fail, we could plan maintenance and downtime in advance, minimizing production losses and keeping operations running smoothly. It’s easy to see how this use case translates to cost and time savings and helps keep production in full swing.
Step 3: Collect & clean data
I repeat this like a mantra, but data is the foundation of any predictive maintenance model – without it, there’s nothing to build on. At this stage, the goal is to integrate information from multiple sources and ensure it’s accurate, consistent, and well-understood. In practice, having data isn’t enough; it’s crucial to know the context behind it.
For example, when a machine undergoes a major service or component replacement, its behavior can change significantly. Even if it’s the same machine in the same building, new parts or adjusted parameters can make it operate differently. I was once part of a project, where the predictive model only improved when we decided to exclude data from before the servicing period. We focused exclusively on the machine in its current state. In that particular context, excluding historical data helped the model better reflect reality.
Understanding the data also means keeping track of maintenance events, process changes, or equipment upgrades that can influence readings. The key is to make sure the model learns from relevant and accurate information, so predictions are reliable and actionable.
Step 4: Choose tools & build models
Selecting tools and building predictive models is highly dependent on the specific use case. In my experience, the choice of platform like Python, R, or a commercial solution is secondary.
What really matters is the nature of the data and the problem. For example, if there’s a large volume of high-frequency sensor data, more complex models like neural networks may be suitable. But if data is limited and simpler, classical models often turn out to be more effective.
The type of prediction, i.e., whether it’s forecasting exact failure times, issuing early warnings, or monitoring operational parameters, also shapes the model choice.
At this point, you should also ask yourself – can data leave the site?
Some factories allow cloud-based solutions, but often sensitive or third-party equipment data cannot leave the site due to compliance or intellectual property restrictions. In those cases, models must run on on-premises infrastructure, even if cloud solutions would be more convenient. The decision also depends on production speed and the need for real-time reactions: fast processes may require local processing, while slower operations can tolerate cloud integration.
Tip: It’s also worth considering “non-obvious” data sources. Visual inspections, for example, are essential in industries like aerospace, where boroscopes detect blade damage during maintenance. Auxiliary sensors can complement existing data and improve model accuracy.
In practice, predictive maintenance is really about working with the data and infrastructure you actually have and building models that give insights you can act on – all while keeping an eye on operational limits, costs, and data security.
Run a pilot
A pilot is where a predictive maintenance project either earns trust or falls apart, that’s why I recommend to always start small. Even an imperfect model has value at this stage, because the goal is to validate direction, not to deliver a final product. A lightweight, experimental version – more than a mock-up, but not yet a full system – gives people on the shop floor something real to react to.
This is the moment when feedback still comes quite cheap. When a near-finished solution lands on a machine and the architecture turns out misaligned with reality, changes become painful and political. A pilot prevents that. It reveals whether the system reflects how operators actually work, not how we assumed they work.
Communication is another reason to pilot early. Production teams speak their own language, and engineers or data teams speak theirs; misunderstandings hide in that gap. An iterative pilot forces alignment through quick cycles of showing, listening and adjusting. Call it agile, or common sense – the more often the future users see the solution, the better the final system becomes.
People on the line don’t care whether the model is a classic algorithm or the latest neural approach. They care that the system alerts them in time and makes their day easier. A pilot ensures you’re building for that outcome, not for the model itself.
Scale & integrate
Scaling should follow the priorities of the factory, not the ambitions of the vendor. Start with a limited footprint, i.e., one site or even a single production line, and expand only after the results are proven. When the system delivers value, then it earns the right to reach more plants, more lines and more assets. Cloud platforms make that expansion straightforward. Adding machines or boosting compute power rarely requires heavy work, but the infrastructure still needs monitoring and constant care.
The real complexity shows up elsewhere. Machinery is rarely uniform, even when the nameplate says it is. Two “identical” machines can differ in instrumentation, configuration and wear history. Industrial equipment is closer to a series of custom builds than a mass-produced product, which means every rollout requires awareness of variation. Scaling is less about copying a model and more about adapting it without losing consistency.
Integration matters more than raw scale. Many predictive maintenance initiatives lean on the cloud by default, because it accelerates development and centralizes data. That approach works well in an office environment, but a production line has a different rhythm and a different cost of failure. If a system drops for even minutes, the financial hit can dwarf the price of the entire project.
That’s why the cloud vs on-prem decision belongs at the very start of system design. It affects architecture, staffing, deployment and how data flows in real time. Cloud speeds up experimentation. On-prem reduces risk in plants where uptime and latency rule. Either path can work, but the choice must be deliberate, debated with the client, and aligned with the realities of the factory, not with IT fashion.
Train teams & monitor
From my experience, technology is rarely the hardest part of predictive maintenance in manufacturing; it’s usually the people who are the most difficult. Adoption succeeds when someone on the shop floor becomes an internal champion, a trusted operator or technician who understands the process, speaks the local language and isn’t afraid to challenge ideas. With a person like that, training becomes a partnership. Feedback flows, the tool evolves in the right direction, and the rest of the crew is far more willing to follow.
Without that ally, the rollout still works, but it takes longer. Training shifts into a series of demos, feedback rounds and hands-on sessions. At that point the project enters a new phase. More users bring more ideas and edge cases, which means more improvements to fold back into the product. That cycle never really stops, and it shouldn’t.
Monitoring follows two tracks – the first is technical. Models drift, data shifts and sensors fail, that’s why a predictive system needs constant oversight so accuracy doesn’t decay. That means watching model behavior in production, retraining on fresh data when needed and having guardrails that recognize whether an alert signals a real issue or just a dying sensor. A solid anomaly layer helps avoid false alarms and keeps trust high.
The second track is about outcomes. Predictive maintenance only matters if it changes reality on the ground. Time between failures, cost of service, number of interventions, workload on maintenance crews – those are the metrics that justify the effort. If the numbers don’t move, the model is noise. If they do, the organization sees proof, not promises.
Finding the best fit for your predictive maintenance needs
Predictive maintenance can cut costs, reduce downtime, and improve safety. The key is starting with clear goals, understanding which assets matter most, and knowing the data you already have. From there, choosing the right tools and models ensures the insights you get are actionable.
From my experience, success comes from grounded, practical decisions that reflect the realities on the production floor, not just theoretical models. Challenges like legacy systems, inconsistent data, or compliance constraints are common, but they can be managed with the right approach.
To learn more, I recommend giving our Predictive Analytics in Manufacturing a read. And if you’re looking for a partner to help assess your needs and plan your predictive maintenance project, visit our data engineering service page to see how we could support you.






