

The project that wasn’t about AI. Until it was
Let me tell you about a project that wasn't about AI at all, but turned out to be the most important AI investment the clients could ever make.
A fast-growing insurtech came to us with a problem. Their policy management system had evolved organically over years. What started as a single application had become a sprawling monolith connected to multiple databases: customer data here, vehicle information there, policy details somewhere else, claims history in yet another system.
Millions of rows. Multiple databases. No common format.
The problem: Fragmented insurance data
They couldn't answer basic questions without heroic SQL gymnastics. "How many active policies do we have?" required joining data from three systems and hoping the customer IDs matched. "What's our exposure in a given region?" was a multi-day project involving exports, spreadsheets, and prayer.
Reporting was slow, unreliable, and expensive. But that wasn't the real problem.
The real problem was that every AI initiative they tried to launch hit the same wall: the data wasn't there. Not missing. Just scattered, inconsistent, and impossible to use at scale.
This isn’t unusual in insurance. Legacy core systems evolve over decades. Claims, policy, billing, and CRM systems are implemented at different times, by different vendors, for different purposes. Over time, the organization accumulates data – but loses coherence.
In insurance, data rarely disappears. It fragments. And fragmented data is functionally the same as missing data when building AI systems.
What “fragmented data” actually looks like in insurance
Why a unified data platform was the only real fix
At that point, the question wasn’t whether to build better reports. It was whether to redesign the data foundation entirely.
Incremental fixes wouldn’t work. Adding another integration layer would only deepen the complexity. Building AI pipelines on top of fragmented systems would replicate the chaos at scale.
The only viable option was to create a unified, governed data platform: a single environment where customer, policy, vehicle, and claims data could coexist under one coherent schema.
That’s where Snowflake entered the picture.
Why incremental fixes wouldn’t work
When data fragmentation is structural, the solution must be architectural.
Building the unified insurance data layer in Snowflake
The project scope was straightforward: migrate everything to Snowflake. Customers, vehicles, policies, claims – all of it, normalized into a coherent structure.
Simple to describe. Brutal to execute.
The source systems were a mess. Different databases used different identifiers for the same customer. Date formats varied. Some systems stored vehicle registration as a single field; others split it across three. Policy statuses meant different things in different contexts.
We built data pipelines using Apache Airflow and Python. Not because it's glamorous, but because orchestrating hundreds of data flows across systems requires something designed for the job. Airflow gave us:
- Dependency management between tasks
- Retry logic for flaky source connections
- Visibility into what ran, what failed, and why
- Scheduling that actually works at scale
The pipelines pulled data from source systems, cleaned it, resolved conflicts, and loaded it into Snowflake's raw layer.
Inside Snowflake, we built the transformation logic. Raw data became staging tables. Staging tables became analytical models. By the end, we had approximately 100 analytical tables – a clean, consistent representation of the entire insurance operation.
Customers had one ID. Identity resolution across systems is one of the hardest problems in insurance data architecture, and one of the most critical for machine learning. Policies had consistent statuses. Vehicles were normalized. Claims linked correctly to policies and customers.
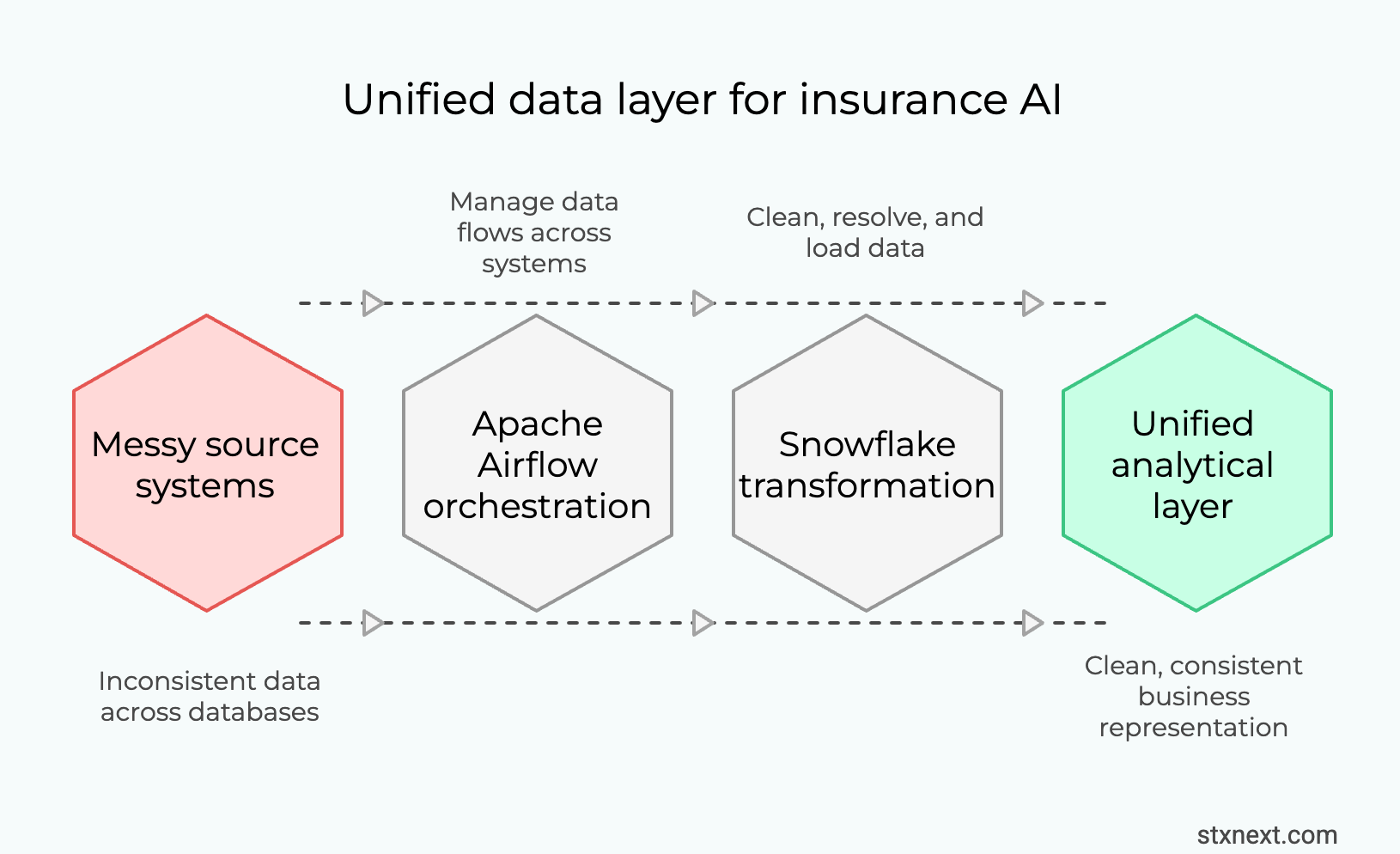
For the first time, the company could query their entire business from one place. This wasn’t just a migration. It was the creation of a unified analytical layer. It's the foundation required for any scalable AI initiative in insurance.
Once customer, policy, and claims data share a consistent structure, feature engineering stops being a research project and becomes an operational workflow.
What “AI-ready data architecture” actually means
Immediate business wins after migrating insurance data to Snowflake
The original goals were modest: better reporting, faster queries, lower maintenance burden.
We delivered all three.
In insurance, the first ROI of a unified data platform is rarely AI. Most often it’s operational clarity, trusted reporting, and faster decision-making.
Reporting that actually works. Dashboards that previously took minutes to load now responded in seconds. Questions that required custom development became self-service SQL queries.
Downstream systems fed reliably. Other applications, like pricing engines, customer portals, partner integrations, could pull from Snowflake instead of hitting production databases directly. Latency dropped. Reliability improved.
Reduced operational overhead. No more manual reconciliation between systems. No more "which database has the truth?" debates. One source, one truth.
In regulated insurance environments, these improvements also reduce audit friction, because reporting becomes consistent, traceable, and governed. Unified governance is also critical for regulatory reporting, capital adequacy analysis, and compliance frameworks such as Solvency II or IFRS 17.
A unified Snowflake-based data platform supports regulatory reporting by providing centralized, governed data models, ensuring consistent identifiers across policy, claims, and customer domains, and enabling full data lineage and traceability.

Quick wins from a unified insurance data platform
These wins alone justified the project. But the bigger payoff was what came next. It wasn’t reporting speed – it was the fact that AI finally became feasible on top of this foundation.
Why this matters for AI
Here's the thing about machine learning in insurance: the algorithms are not the hard part.
Fraud detection? The statistical techniques are well understood. Dozens of papers, open-source implementations, cloud services ready to deploy.
Dynamic pricing? Gradient boosting on policy features. Not trivial, but not rocket science either.
Churn prediction? Same story. The models exist. The math is solved.
What’s not solved (and rarely discussed at board level) is the data architecture behind those models.
To build a fraud detection model, you need:
- Complete claim histories linked to policies and customers
- Behavioral patterns across interactions
- External data enrichment (device fingerprints, location signals, third-party risk scores)
- Consistent labeling of what actually was fraud
To do dynamic pricing, you need:
- Accurate exposure data by risk segment
- Claims history at the right granularity
- Customer attributes that are actually populated and correct
- Fast feedback loops between pricing changes and outcomes
None of this is possible when your data lives in six different systems with incompatible schemas.
The Snowflake migration didn't build AI. It made AI buildable.
What insurance AI actually requires
Advanced fraud detection in insurance: What a unified data platform enables
Let me paint a picture of what's now within reach.
Insurance fraud is a $80+ billion problem globally. Traditional detection relies on rules – if claim amount exceeds X, flag for review. If the claimant has Y history, investigate.
Rules catch obvious fraud. They miss sophisticated schemes.
Rules-based vs behavioral fraud detection
Modern fraud detection uses behavioral biometrics and pattern analysis:
- How does this user interact with the claims portal? Mouse movements, typing patterns, session duration. Legitimate claimants behave differently than organized fraud rings submitting templated claims.
- Does this claim pattern match known fraud networks? Graph analysis across policies, addresses, phone numbers, device fingerprints. Fraud rings reuse infrastructure.
- Is this claim consistent with the customer's history? Someone who's been a customer for five years with no claims submitting a suspicious total-loss claim looks different than a new customer doing the same.
This kind of analysis requires joining data across domains: customer behavior, policy history, claims patterns, device signals, external risk data. It requires historical depth for training. It requires fast inference for real-time scoring.
None of this works without a unified data platform.
Without unified architecture, behavioral fraud detection remains a slide in a strategy deck.
With Snowflake as the foundation, you can:
- Stream behavioral events into the same warehouse where policy data lives
- Build ML features that span domains (customer + policy + claims + behavior)
- Train models on years of historical data without sampling
- Deploy scoring models using Snowpark for real-time inference
- Feed results back to downstream systems for automated decisioning
The infrastructure is the enabler. The AI is the application.
Architecture requirements for behavioral fraud detection
Why platform design matters more than model selection
If I had to summarize years of data and ML projects in insurance, it's this:
Teams that start with "what model should we use?" fail.
Teams that start with "how do we get clean, unified data?" succeed.
Platform-first vs model-first AI strategy
The model is the last 20% of the work. The first 80% is:
- Getting data out of legacy systems
- Resolving identity across sources
- Building transformations that business users can trust
- Creating feedback loops for continuous improvement
- Designing for evolution, not just initial deployment
Snowflake isn't magic. But as a modern cloud-native data platform, it removes structural bottlenecks that legacy insurance architectures struggle with.
Snowflake solves real problems:
- Separation of storage and compute – store everything, pay for compute only when needed
- Native support for semi-structured data – JSON from APIs, nested event data, external feeds
- Snowpark for ML – Python and ML libraries running where the data lives, not copied elsewhere
- Scalable sharing – feed downstream systems, partners, and models from one governed source
The platform decision shapes what's possible downstream. Choose well.

In insurance, AI maturity is less about data science talent and more about data architecture discipline.
The real truth: Why data platforms, not models win in insurance AI
The insurtech we worked with didn't deploy a fraud detection model. They didn't launch dynamic pricing. Not yet.
What they did was build the foundation that makes those projects viable.
Before: every AI initiative would start with a six-month data wrangling project, with uncertain outcomes and frustrated data scientists.
After: teams can access clean, consistent, queryable data from day one. Feature engineering takes weeks, not quarters. Model iteration is fast because data iteration is fast.
That's the unsexy truth about AI in insurance. The winners won't be the companies with the best algorithms. They'll be the companies with the best data platforms.
The models will come. The data has to come first.
Key takeaways for insurance technology leaders, CTOs and Heads of Data:
- AI initiatives stall when data architecture is fragmented
- Unified platforms like Snowflake make cross-domain ML feasible
- The first ROI comes from reporting and operational trust
- Models scale only when data governance and identity resolution are solved
Where to start if you want AI in insurance
- Identify high-value domain (fraud, pricing, claims)
- Audit fragmentation across systems
- Build unified governed data layer
- Run one pilot use case with clear ROI
- Scale only after workflows adopt it
Building an AI-ready data platform? Stuck in migration hell? We've done this before: the messy legacy extraction, the painful normalization, the Snowflake architecture that actually scales. Let's talk about what's blocking your AI ambitions. Get in touch with us→






