

Data lakehouse: Why strategy fails before technology does
Data lakehouses are one of the most capable architectures available today. They combine the massive scale and low cost of data lakes with warehouse-level reliability - all in one unified platform. Yet in practice, many lakehouse initiatives stall, overrun budgets, or quietly underdeliver.
In my experience, it’s rarely the technology that lets organizations down. Platforms like Databricks and Snowflake are mature and deliver when handled correctly. The gap almost always comes down to execution: realistic planning, the right skills on the team, and careful attention to data quality and engine nuances.
The single-biggest, repetitive mistake I’ve seen is treating data lakehouse adoption as a “simple” move or quick plug-in.
Below, I explain this and other common reasons for failed data lakehouse initiatives. I also share what companies can do to move to the new architecture without disruption and project delays.

Common reasons data lakehouse projects fail
Poor governance
Even with the best tech in play, data lakehouse projects can trip up if planning or execution falls short. Poor governance is one of the primary reasons data lakehouse initiatives fail at scale. This turns your shiny lakehouse into a dreaded "data swamp". A chaotic jumble of data that's hard to navigate, understand, or trust.
This mess often stems from skimping on metadata management and governance basics. Without a solid data catalog, clear ownership assignments, and validation rules, your repository fills up with questionable data that no one can rely on.
Take mergers or acquisitions as a prime example. I've seen this play out firsthand in projects where companies combine forces. Suddenly, teams realize they're not speaking the same language. A term like "leads" might mean one thing in your original setup (say, any website inquiry) and something entirely different post-merger (only qualified prospects). Or consider "user session": Is it based on login time, scroll activity, or something else?
These mismatched definitions lead to metrics that tank on paper, sparking confusion and complaints from stakeholders. "Why are our numbers down?" they ask, when really, it's just inconsistent metadata at work.
Prioritizing strong governance from day one is key to data lakehouse best practices, ensuring everyone aligns on definitions and data quality before things spiral. This not only prevents swamps but sets the stage for smoother adoption and real business value.
Unreliable data quality
Another reason why data lakehouses fail to deliver is that they ingest raw data from many source systems without adequate cleansing or validation. If data quality checks aren’t built-in, errors and duplicates will flow downstream and corrupt analyses and AI models.
The extent of the problems will vary by business. For example, a SaaS company pulling structured license-usage logs from internal systems or partner APIs typically deals with cleaner, more predictable feeds. But an e-commerce operation like Amazon faces a different reality, because every login, click, or purchase event streams in through complex backend pipelines prone to retries.
A network glitch, timeout, or automatic retry could duplicate the same event. Delivery guarantees complicate matters further. A rule like “at least once” allows duplicates to avoid loss, while “exactly once” still fails when upstream systems retry independently. This pattern appears across AWS, GCP, and custom setups alike.
No source delivers perfect, duplicate-free data consistently by itself. The distributed nature of these systems makes it impossible. That’s why data engineering teams must own deduplication and validation within their own pipelines.
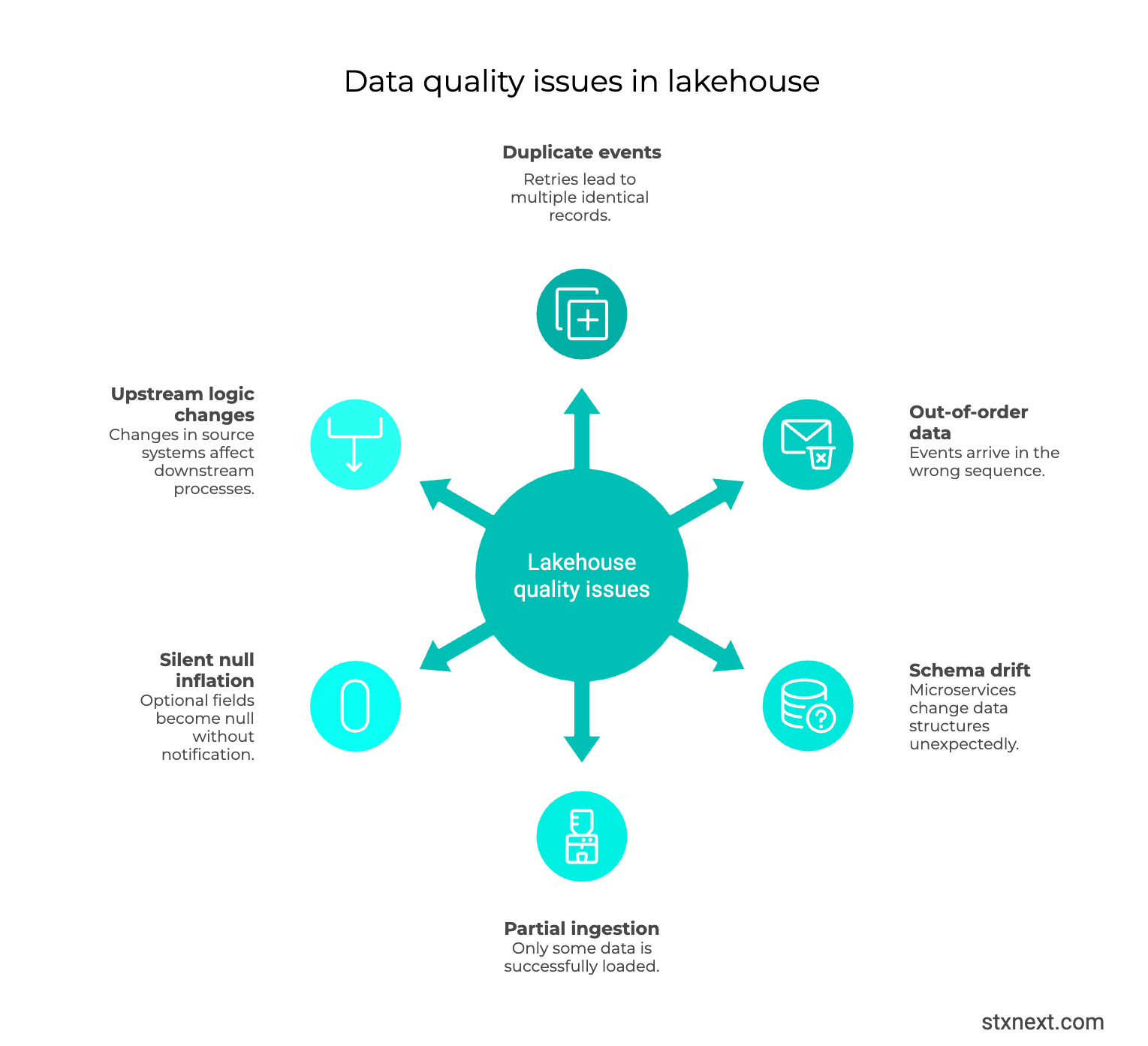
Lack of a semantic layer
A data lakehouse is great at pulling together huge volumes of data in one scalable spot, mixing lake flexibility with warehouse structure. But just having all that data centralized doesn't magically turn it into actionable insights, especially if business users and analysts can't easily pinpoint or trust the exact metrics and KPIs they need.
The issue often boils down to missing a proper semantic layer (or some form of unified metrics definitions). Lakehouse platforms tend to be built with data engineers in mind, so without that abstraction layer, a data catalog, or a truly self-service interface, non-technical users end up stuck waiting for help.
Even for those closer to the tech side, the real pain point isn't usually "can't find the table" – it's more subtle. A metric like "active users" or "revenue" might exist in multiple variations with slightly different calculations or filters. Without a semantic layer enforcing a single source of truth, different teams end up building reports from mismatched definitions.
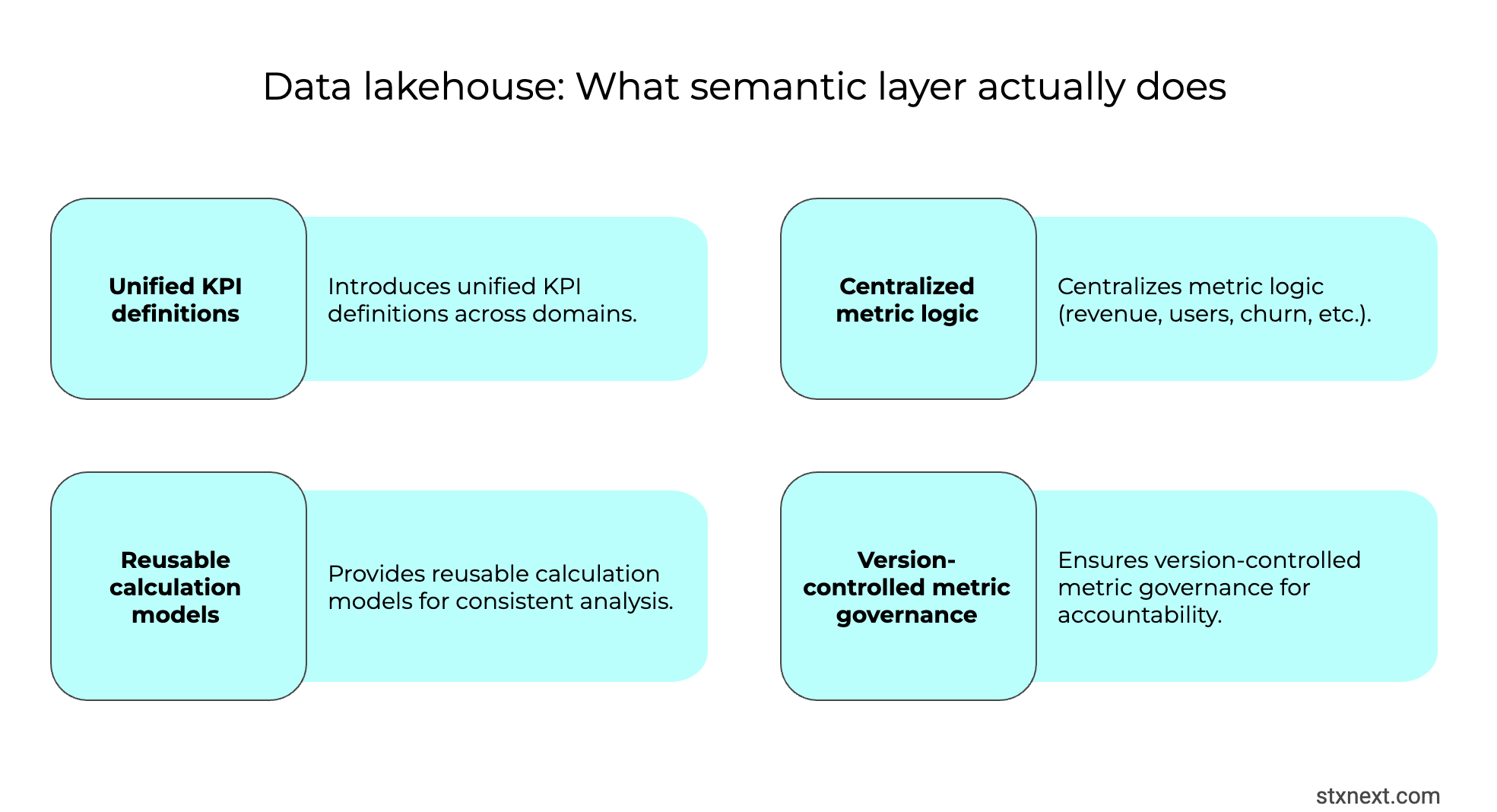
I've seen this crop up especially during growth phases (mergers, new regions, or product expansions) where definitions that used to be consistent suddenly aren't. Business stakeholders notice the discrepancies first: "Why does this KPI look off?" This is because of a lack of a clear, shared business meaning layered on top of the raw data.
This gap is why many lakehouse projects underdeliver on the promise of self-service analytics. Adding a semantic layer from the start ranks high among data lakehouse best practices, it makes metrics consistent and reusable for everyone, not just engineers.
Over-engineering and unrealistic expectations
Teams often fail when they try to build everything at once – real-time streaming, full ML pipelines, intricate MLOps, and multi-cloud federated queries. In my experience, this context switching can stretch project delivery far beyond plan.
A related trap is the “silver-bullet syndrome”. In the case of data lakehouse initiatives, it’s the belief that adopting a lakehouse alone will instantly fix every data problem. In practice, the lakehouse is an evolving platform, not a finished endpoint. Treating it as a final destination raises the odds of failure, either during migration or later when the organization outgrows it.

The mismatch becomes painfully clear when organizations attempt a full warehouse replacement on an aggressive schedule. Engineers familiar with traditional warehouses jump to complex lakehouse setups like multi-environment Databricks deployments, expecting massive scale and speed in months. Without deep expertise in the new stack, those two-month estimates could turn into years. That would mean a >10x overrun in time and cost.
This is also related to the next mistake below.
Skills and culture gaps
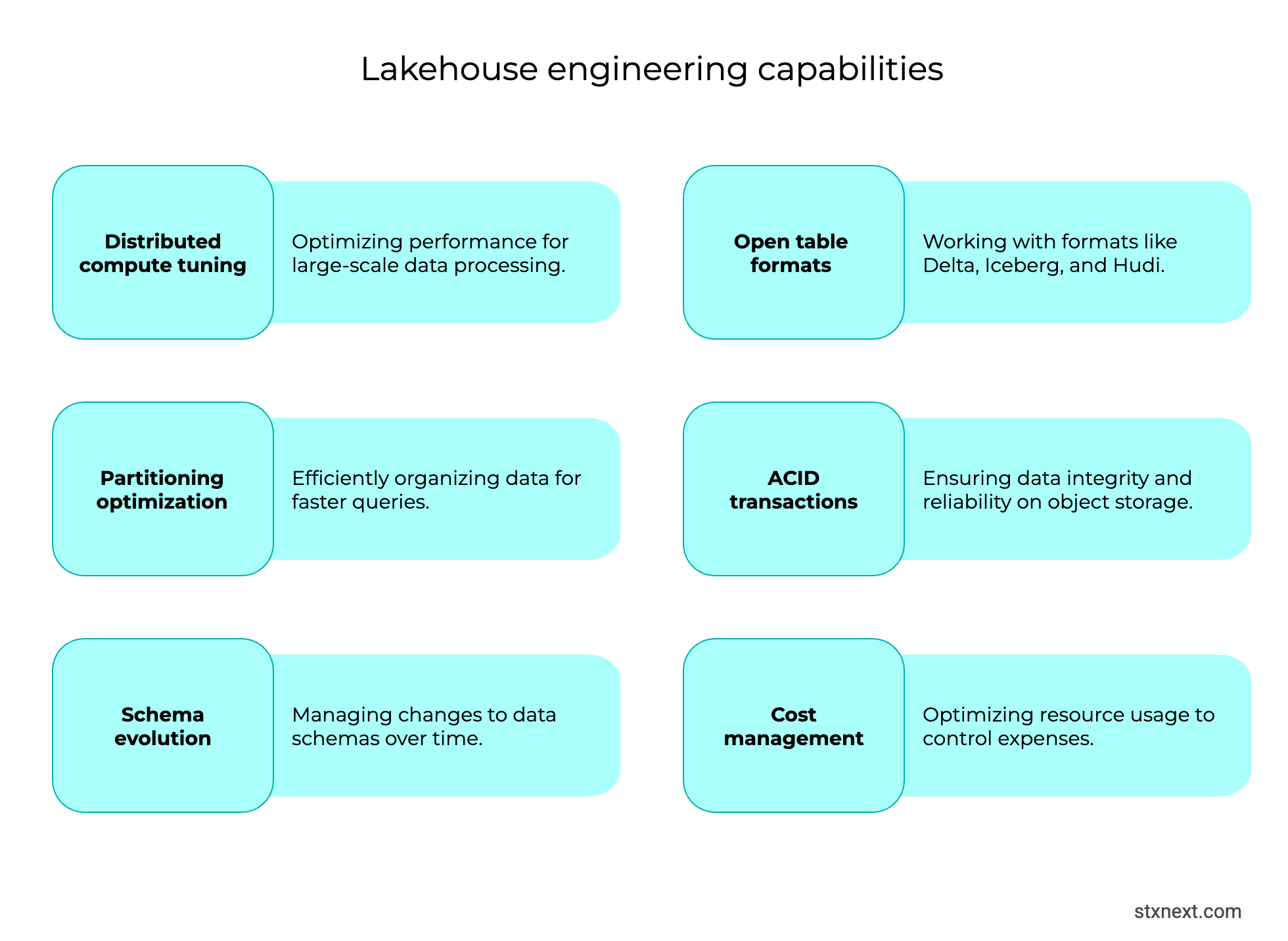
A data lakehouse demands data engineers skilled in distributed cloud platforms, streaming, and open table formats. Warehouse specialists handle SQL and ETL well, but lakehouse setups bring unfamiliar challenges like scale partitioning, ACID on object storage, and schema evolution. If you don’t hire talent or upskill your existing engineers, they might quickly come across issues with misconfigured tables, runaway query costs, and exposed security holes.
Business-side readiness matters, too. Without teams primed for self-service analytics like querying raw data and trusting the platform, the lakehouse goes unused.
Cost overruns and performance issues
One of the quickest ways data lakehouse projects lose steam is ballooning costs paired with underwhelming performance at scale.
Cloud storage feels cheap at first, but when you're dealing with hundreds of terabytes (or more), even that starts to hurt. The real killer, though, is compute. Processing and querying massive datasets can send bills through the roof if left unmanaged.

Common traps include spinning up oversized clusters for minor jobs, leaving resources running 24/7, skipping query tuning, or letting unused/old data accumulate because "storage is inexpensive." At enterprise scale, those habits add up fast. I've seen this across platforms – Snowflake, Databricks, and similar lakehouse setups – where teams don't right-size resources or proactively clean house. Suddenly the invoice arrives, the ROI looks shaky, and stakeholder buy-in vanishes.
This isn't lakehouse-specific; it's a modern data-platform reality. But without discipline, the promise of cost-effective scale turns into "bill shock."
That's why cost and performance management is non-negotiable in data lakehouse best practices.

Why data lakehouse initiatives fail: Structured breakdown
Strategic best practices for data lakehouse implementation
Implementing a data lakehouse is a transformative shift, not just a technical upgrade. Here’s what I recommend based on the data lakehouse projects I’ve been part of.
1. Begin by assessing data lakehouse readiness and define the transition path
The first step is identifying the organization’s starting point.
So, the question here is: are you building a lakehouse from scratch? This could be the case of a startup shifting from basic backend databases toward AI-powered systems or solutions.
Or are you a larger organization migrating from a legacy data warehouse to a scalable modern platform? If it’s the latter, recognize early that moving away from a legacy system is never merely a technology swap.
It’s going to demand a thorough examination of the target architecture – whether you’ve decided on Databricks, Snowflake, BigQuery, or another. It also requires an evaluation of whether your current team has the depth to manage the initial complexity of the move without major stumbles.
To do that, I recommend running a rigorous feasibility and cost assessment of the chosen platform. If you're considering working with an external partner, experienced data lakehouse consulting services can help validate the target architecture, estimate migration costs, assess technical readiness, and design a realistic implementation roadmap before major investments are made.
2. Manage expectations and timelines
As mentioned earlier, unrealistic deadlines are the most common trap. A three-month plan can stretch into a year if you don’t account for unpredictable events like schema mismatches, ingestion failures, query tuning issues, or security adjustments. These “minor” problems are standard in foundational changes. Yet, you won’t find them in overly-optimistic schedules. It’s quite realistic that the result could be a severe overrun in time and cost.
Resourcing must match reality. The migration phase typically requires more capacity than ongoing operations. Relying on the same small team to handle discovery, design, testing, cutover, and parallel runs leads to delays, burnout, and quality drops.
Budget for temporary headcount spikes, specialized contractors, or dedicated training time upfront. Also, approach the project with honesty: this is a deliberate, phased shift that rewards measured pacing over aggressive speed. Plan for the true weight of the change, and your organization will be far more likely to deliver value without collapse.
3. Prioritize data quality and engine logic
Here’s where many of the “silent” failures occur. Even identical SQL queries can produce different results because engines handle math operations (like rounding, decimal truncation, or floating-point precision) differently. A tiny variance on one row could compound into million-dollar discrepancies when summed over millions. On the company level, it could break your organization’s key business metrics.
What I recommend is investing in rigorous, side-by-side validation early on. This includes running parallel queries on legacy and new systems, automating tests for high-stakes aggregates (think: revenue, inventory, costs), and using platform-native tools for profiling, anomaly detection, and reconciliation.
Make sure that your data team documents engine-specific behaviors upfront and adjusts logic accordingly. Such quality checks will help the new engine deliver consistent and trustworthy outputs that match or surpass the old system.
4. Implement proactive cost optimization
A data lakehouse can scale forever – and so can its costs. The best approach is to bake efficiency in from the start, before bills become a problem.
Focus on incremental loading: use watermarking or change tracking to process only new or changed data instead of re-running full datasets. This keeps jobs fast, clusters small (or serverless), and compute spend way lower.
Smart storage design pays off immediately. Partition by date or key dimensions and cluster on frequently filtered columns so queries scan only what’s needed, no more full-table reads eating credits.
Tier your storage aggressively. Shift cold, seasonal, or rarely accessed data to cheaper archival tiers (via external tables). There’s no sense paying premium rates for data you touch once a year.
Be ruthless with testing, too. Write targeted, optimized tests that validate essentials without scanning giant tables – sample where possible, use views, or limit scope.
5. Bridge the skills gap
Adopting a lakehouse pushes traditional data warehouse engineers into modern data engineering and DevOps territory. The old SQL-only world expands; teams must adapt or the platform will stall.
Prioritize mastery of current standards like dbt for modeling and transformations. It’s become the go-to tool for clean, version-controlled pipelines. Engineers should treat it as core, not optional.
Cloud and ops skills are essential, too. Move beyond stored procedures to Git workflows, infrastructure as code, monitoring, and cost-aware resource management. Lakehouses demand engineers who can build, deploy, and operate distributed systems reliably.
Embrace flexible design patterns rather than rigid schemas. Know when Star/Snowflake suits fast reporting, when denormalized works better for ML, or when domain-driven approaches fit large orgs. The skill is matching the pattern to business goals like BI speed, analytics agility, ML readiness without dogma.
Invest in upskilling through targeted training, hands-on projects, or early experienced hires. When the team bridges this gap, the lakehouse becomes a powerful, adaptable foundation instead of a skills bottleneck.
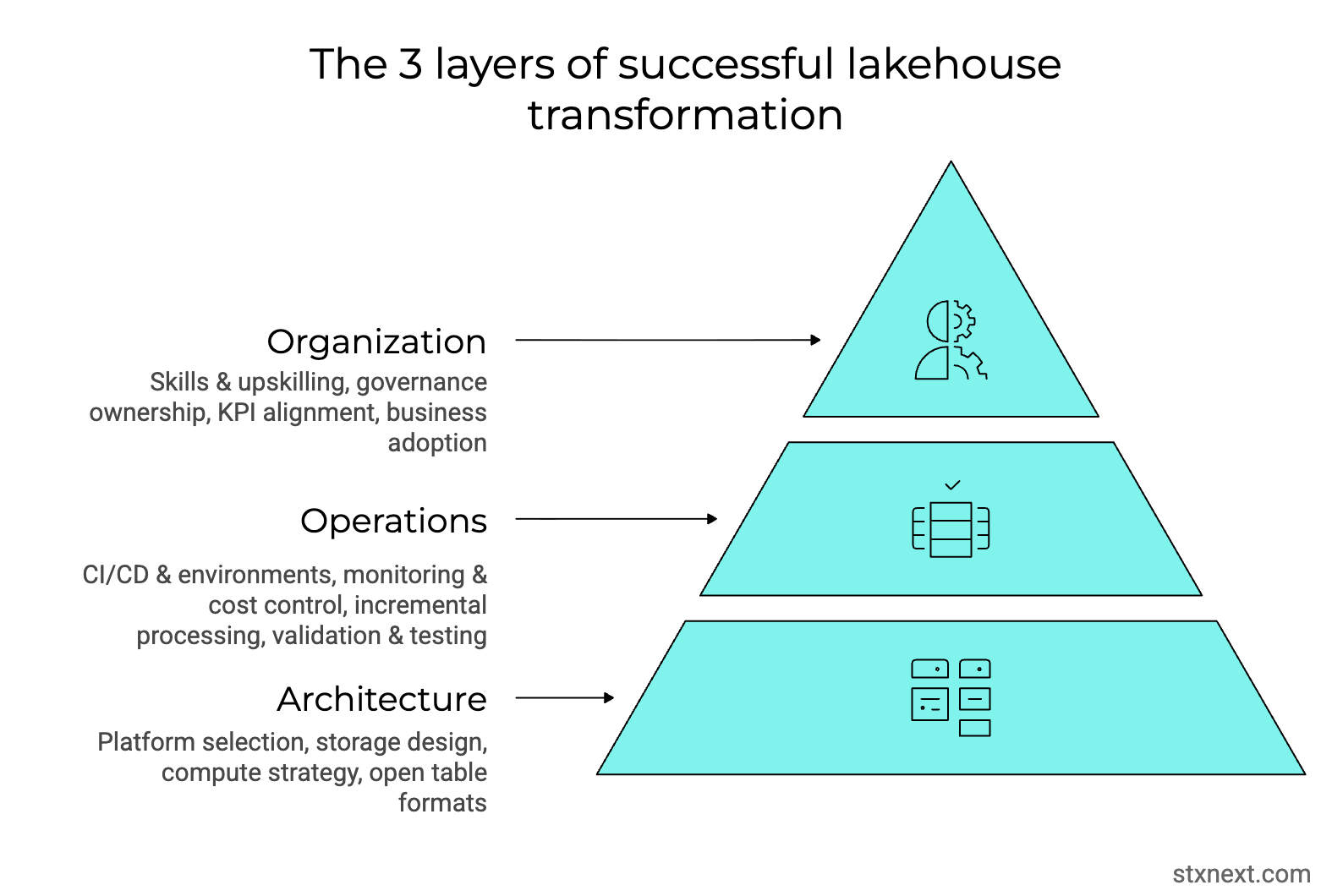
6. Characteristics of a well-maintained lakehouse
A healthy, long-term lakehouse stands out for its clarity and ease of use. Clear ownership assigns accountability for every dataset, while a medallion structure – Bronze (raw), Silver (cleaned), Gold (business-ready) – creates progressive trust levels and logical separation.
Strong visibility comes from rich metadata, lineage tracking, and a reliable data catalog, enabling analysts and BI teams to discover and understand data independently.
Disciplined environments keep chaos in check. Distinct dev, staging, and production setups with automated orchestration and promotion gates ensure safe, predictable changes.
Ultimately, the focus stays on exposure, seamless delivery to end users through intuitive interfaces and minimal friction.
Summary: Lakehouse failure vs success map
The lakehouse success matrix

The lakehouse execution framework
Conclusion & next steps
Many companies build timelines around best-case vendor scenarios and rarely account for the unpredictability of potential issues like schema mismatches, performance surprises, or team upskilling challenges. In my experience, that’s what drags most delayed projects far beyond their original deadline (and budget).
The fix lies in a balanced “holistic” approach. Remember to anchor the project in clear business goals and build strong governance from the start. During the implementation, focus relentlessly on making data usable and trustworthy.
If you're planning a lakehouse migration or evaluating Databricks, Snowflake, or BigQuery as your next data platform, start with a structured readiness assessment before committing to timelines or budgets. When governance, quality, cost control, and skills development evolve together, the lakehouse becomes a strategic asset instead of an expensive experiment.






