

Claims intake is often the hidden bottleneck in insurance operations
Most claims operations treat intake as an administrative step. In practice, it is often where the most expensive delays begin, before assessment, before inspection, and before any meaningful work on the claim has started.
This article distills the key lessons from a six-hour workshop in which our AI team worked with an insurance company handling around 200,000 claims a year across 20 insurers and more than 600 insurance products. Business and technical stakeholders mapped the claims process end to end, identified where time was being lost, and prioritised automation opportunities based on feasibility, cost, and expected ROI.
To make the findings actionable, we built functional prototypes showing what a faster, more automated intake flow could look like in practice.
What follows is what that process revealed.
Why manual intake creates so much friction
What made manual intake costly was not just the volume of work at the front of the process, but the fact that the work often had to be repeated before a claim was ready to move forward. In multichannel environments, that burden grows further because incoming submissions vary widely in format, structure, and quality.
In practice, the friction came from three sources:
- Operational effort – repeated tasks still required consistent human judgment
- Blocked process flow – incomplete submissions prevented claims from becoming assessment-ready
- Poor scalability – more volume meant more repeated handling, not better flow
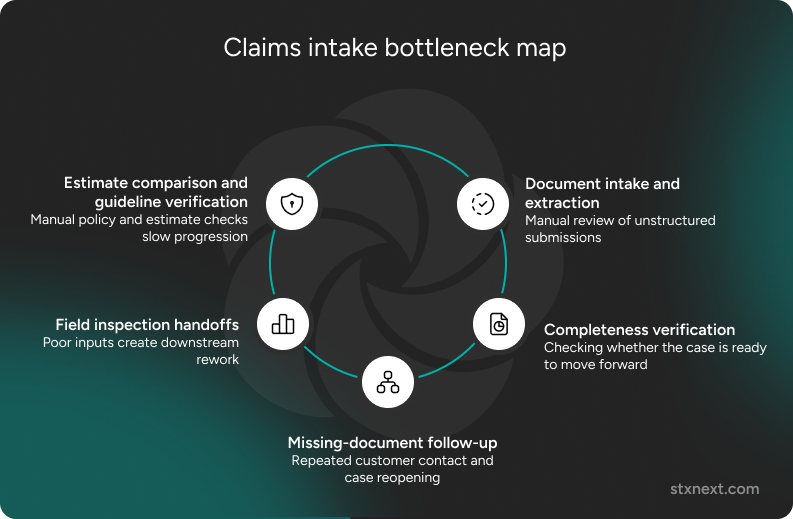
Where time is lost before assessment begins
Document intake and extraction
One of the first friction points visible in the review was document intake itself. Claims were arriving through multiple channels and in different formats, which meant someone first had to open, read, interpret, and route the submission before any real assessment work could begin. Because the quality and structure of incoming material varied so much, the effort was not just manual, but also hard to standardize and predict.
Completeness verification
Another recurring source of delay was completeness verification. A claim might appear ready to move forward, only for a missing attachment, identifier, or key detail to surface later and interrupt the workflow. What made this particularly costly was the fact that it was often discovered after the case had already consumed additional handling time.
Communication about missing documents
The review also showed how quickly incomplete documentation turned into repeated operational work. Once a gap was identified, the process shifted back to the customer: prepare the request, send it, wait for a response, reopen the case, and review it again. What looked like one missing element often became several extra touches before the claim could move forward.
Field inspection handoffs
A similar pattern appeared in the handoff between intake and field inspection. When adjusters received incomplete or low-quality information, they were left with uncertainty about what needed to be captured, how evidence should be documented, or whether the material collected would be sufficient later in the process. In practice, that meant more inconsistency at the point where the claim should have started becoming clearer.
Estimate comparison and insurer-guideline verification
The review also pointed to estimate comparison and insurer-guideline verification as a time-intensive step, especially when source material was inconsistent. Teams had to compare estimates against insurer-specific rules, pricing expectations, or internal policy requirements before the claim could progress. The work was not always complex in itself, but it was difficult to do quickly when inputs varied in format and quality.
Why rework is one of the most underestimated costs
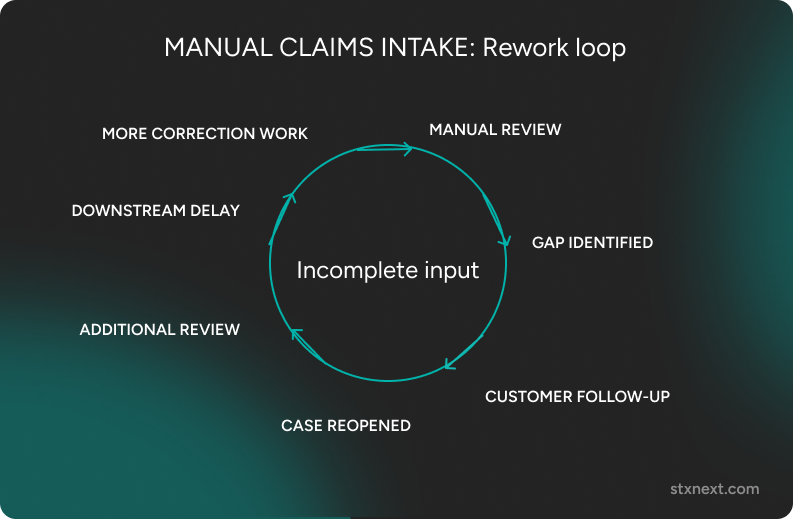
Rework was one of the most underestimated costs visible in the review, because poor intake data rarely stayed in intake. Poor photos, missing identifiers, incomplete documentation, or weak claim descriptions kept returning later as correction work. Instead of creating one isolated delay, they triggered extra handoffs, interrupted flow, and made workloads harder to predict across multiple stages of the process.
Field documentation made this especially clear. When observations were captured manually and then rewritten or restructured later, the same work was effectively being done twice. What looked operationally normal turned out to be a real and repeatable source of inefficiency.
What the prototypes we built showed about claims intake
The prototypes that the AI team at STX Next built for this claims processor were built to test specific intake scenarios in the client’s actual process and to help stakeholders evaluate automation opportunities in more practical, investment-ready terms.
Multichannel intake classification
The first prototype monitored and analysed claims submissions from multiple channels, classifying incoming cases, supporting routing, and generating next process steps from data already available.
This directly addresses the core intake problem: incoming information stays unstructured until someone manually interprets it.
An automated classification layer removes that dependency for the majority of straightforward cases.
Early completeness detection
Instead of waiting for manual review to uncover missing elements, this prototype identified documentation gaps earlier in the process and triggered the appropriate follow-up automatically.
The result is shorter idle time and faster readiness for assessment. The case does not enter the workflow only to stall once a missing element surfaces.
Mobile field assistant
This prototype gave field adjusters an active guide through the correct evidence-collection flow, rather than a passive recording tool.
The difference matters: guided documentation reduces the likelihood that poor inputs will create correction work downstream. It shifts the operation from fixing bad evidence after the fact to collecting better evidence in the first place.
In straightforward cases, computer vision also analyzed submitted photos to detect damage and generate structured technical descriptions automatically, reducing the need for manual write-up.
Voice-to-text field reporting
Instead of manual note-taking followed by later transcription, adjusters could capture observations naturally and convert them into structured descriptions.
This reduces friction at the point of capture and eliminates the duplicate effort that comes from translating handwritten or verbal notes into a system entry.
Estimate comparison and policy verification
Comparing estimates manually against insurer logic, company policy, or regional standards is time-consuming and prone to variation. This prototype supported that analytical step, reducing the manual effort involved without removing human control at the decision point.
Early cost estimation
A sixth prototype focused on early-stage cost estimation, using initial claim data to approximate the likely value and complexity of a case before a formal estimate was prepared.
Using an LLM-based model, the system approximated the cost of damaged elements from the initial submission data. This gives claims handlers an early signal about case complexity and helps prioritize which claims need the most immediate attention.
What the prototypes pointed to
Taken together, the prototypes pointed to a different operating model: one in which detection happened earlier, inputs were structured closer to the point of creation, and correction work became the exception rather than a routine part of the day.

Fraud detection as an automation opportunity
Beyond the six prototypes, the workshop also surfaced fraud detection as a distinct automation opportunity.
Dedicated machine learning models can flag patterns consistent with fraudulent or inflated claims, adding a layer of verification that is difficult to apply consistently at scale through manual review alone.
What business impact from claims intake automation is realistic?
The clearest business case here is time. Based on the mapped bottlenecks and prototype validation, the working assumption discussed in the project was that end-to-end claims handling time could potentially be reduced by around 30%.
But the bigger point is not just speed. If you improve intake in the right places, you are not simply making claims move faster. You are changing how the process works: detecting missing information earlier, improving input quality closer to the point of capture, and reducing the amount of correction work pushed into later stages. Instead of absorbing friction through queues and repeated handling, you can design for smoother flow from the start.

That shift also changes what customers experience. A slow claim often feels like silence, repeated requests for information, or uncertainty about what happens next. Intake-stage delays rarely stay internal for long. Moving claims forward faster and more consistently can improve both retention and trust.
Why this is worth fixing now
Delaying intake improvements does not preserve the status quo. It usually means scaling the same friction into higher claim volumes, carrying more rework into downstream stages, and giving competitors more time to improve claims speed, consistency, and customer experience through automation. The longer you wait, the more expensive catching up becomes.
How to tell whether claims intake is the right place to start
If intake remains manual, fragmented, and prone to missing information, the rest of the operation will continue to absorb the cost through rework, blocked flow, queue growth, and slower service.
Before investing in automation, measure where claims are delayed before they become ready for assessment:
If those patterns are common, claims intake is probably a bottleneck worth fixing first.
It is also worth separating simple claims from complex ones before drawing conclusions. They create different documentation needs, operational patterns, and delay risks, and measuring them together can hide both the scale and the source of the problem.
Once the main sources of delay are visible, the right automation priorities become much easier to define. You can see where repeated handling is unnecessary, where better input quality would reduce downstream friction, and which intake-stage improvements are most likely to improve claims flow first. Learn how we help insurers identify and automate high-friction stages in claims handling.






