

The production reality behind agentic AI
When an agentic AI system breaks down in production, the postmortem rarely blames the model itself. Instead, it exposes flaws in the infrastructure around it.
In production, agentic AI depends on backend architecture, orchestration, observability, permissions, and integration design as much as on model capability.
While online hype stays hyper-focused on the LLM layer, practitioners who actually ship production systems face a completely different reality. The consensus among engineering teams is that backend architecture, orchestration, and deep observability matter far more than raw model quality.
To move an agent from a demo to production you’ll have to move past basic prompt engineering, and focus on solving classic, complex infrastructure problems.
Here is why your backend dictates your agent's success.
What makes an AI agent different from a regular LLM app
I’ve noticed that some companies, particularly those that don’t operate in the tech field themselves, think of agents as “just LLM apps, but more capable”. The fact is, however, that they behave more like distributed systems with a language model in the middle.
The first crack in that assumption shows up in determinism (or rather, the lack of it).
LLMs are inherently non-deterministic. We shouldn’t think of it as a temporary limitation or something that can get better with improved prompts. It’s a direct consequence of both the model architecture and the way we use them, i.e., stateless API calls to systems we don’t fully control.
Like LLMs, agents can answer questions, but they also take actions, make decisions, and chain calls across tools and other agents. The moment you give them that freedom, you lose the ability to reliably reproduce behavior. If you run the same scenario five times, you’ll get five slightly different trajectories every time.
Since there is no single “correct” output to assert against, confidence stops being binary and starts looking like probability distributions.
This relates to another trade-off here that’s easy to overlook – the more flexible the system, the harder it is to evaluate. And agents, by design, maximize flexibility.
The second difference is more subtle (and perhaps even more dangerous). In agentic systems, a large class of failures is effectively invisible.
An agent calls a tool with slightly wrong data. Another agent picks up incomplete context. A piece of state isn’t updated on time, and somewhere along that chain of events, the model hallucinates in an intermediate step. The fact that they don’t always take place in the end output makes them that much harder to detect. They degrade systems rather than crash them altogether.
As we can see, we're looking at a set of very different engineering problems in agentic AI.
Agentic AI infrastructure: Why agentic AI systems fail in production
The tool overload pattern
You can build a great agentic AI system in a test environment, but production ruthlessly exposes structural flaws. The most common breakdown happens right at the start of the execution chain, i.e., when the agent selects the wrong tool.
This failure rarely stems from a flawed LLM. More often, a bloated backend environment causes the issue. When you integrate protocols like the Model Context Protocol (MCP), you get quick access to pre-built toolsets, but you also introduce unnecessary noise.
A single MCP server can bring dozens or even hundreds of tools into the system. In a recent project I took part in, an off-the-shelf integration brought 70 tools into the environment, even though the specific business logic required only five.
When your agent chooses between 10 options, it maintains a solid baseline for success. If you scale that library to 100 tools, the probability of a correct choice drops dramatically. Even with a minor 5% error rate, a massive toolset causes frequent missteps, which lead to broken workflows and failed requests.
To fix this, you must restrict the context. Clients rarely understand the underlying mechanics of tool selection, so the responsibility falls on you, the developer, to curate the environment. Academic research confirms that performance drops significantly once an agent must choose from more than 20 or 30 tools. If you limit the backend to a handful of essential, high-impact capabilities, you remove the cognitive load from the LLM and establish system stability.
The context window overflow
Standard testing rarely prepares you for how real users interact with a production chatbot. In development, you test clean, straightforward scenarios. In reality, a user might keep a single chat session alive for weeks, piling messages into the queue until the context window explodes.
When you overload the context, performance takes a massive hit. You run directly into the "needle in a haystack" problem where the LLM struggles to find the relevant information buried deep inside the massive history. Eventually, the agent either fails completely due to strict token limits or begins to output total nonsense.
Clients rarely foresee how complex these real-world conversations will get, so your backend must handle the history. You need to implement rolling context windows for a given number of messages, run background summarization loops, or move older history into a RAG setup.
The hallucination trap
Hallucinations quickly ruin production agents, but you can build strong guardrails on both sides of the system. On the input side, a dedicated LLM check ensures the user provides enough data before the agent even triggers. For critical workflows, run three independent calls in parallel and use an "LLM as a judge" to pick the best output.
Unbounded reasoning loops
Another common failure pattern is the agent getting stuck in a loop of:
reasoning → tool call → reasoning → tool call.
Without constraints, this can continue indefinitely. The agent appears to be making progress, but keeps circling around the same steps without getting closer to a valid result.
There are two results of such a situation. We’re looking at longer response times and rapidly increasing costs, especially when each iteration involves multiple model and tool calls.
A practical safeguard would be to limit the number of iterations or tool calls (for example, capping them at 10 or 15). If the agent doesn’t reach a satisfactory outcome within that boundary, the system returns the best available result or moves the workflow forward. The exact limit depends on the use case, but without it, agents don’t have a natural stopping point.
Over-permissioned agents
If an agent has permissions to modify or delete data, it can execute those operations just like any other tool call. A misinterpreted instruction or flawed intermediate step can result in deleting files or wiping database records. There have already been cases where agents removed entire datasets in production environments. The system followed its internal logic, but with too much authority and too few safeguards in place.
Limiting permissions, adding approval layers for destructive actions, and isolating critical systems all help reduce the blast radius. Agents are far more predictable when their capabilities are tightly scoped to what’s necessary.
Backend guardrails for agentic AI: security, observability, and the reality of production math
When an agent moves past basic testing and interacts with live corporate systems, the architecture must shift from generative flexibility to strict backend control. You cannot treat agentic safety or monitoring as an afterthought; these must be core backend design requirements from day one.
1. Security control and the human circuit breaker
Even the most optimized agent operates on probabilistic logic. It will fail a percentage of the time. Because you cannot eliminate this statistical margin of error, critical actions require programmatic constraints.
For high-risk operations, like database deletions or financial transactions, the backend must intercept the execution chain and route the process into a strict Human-in-the-Loop (HITL) workflow. The system halts until a human operator verifies the tool selection and validates the extracted parameters.
For standard, non-critical enterprise actions, you can build an automated, multi-model validation layer to check intent:
- Intent and policy analysis. Before a tool executes, a secondary LLM inspects the primary agent’s reasoning. It evaluates the plan against safety parameters: "Does this action match company policy?" or "Is this request secure?"
- Cross-model consensus Different LLM providers (e.g., OpenAI vs. Anthropic) exhibit distinct logical weaknesses. By running three separate models in parallel, you can establish an evaluation quorum. For standard operations, a simple two-out-of-three majority vote grants execution permission. For higher-stakes paths, a single dissenting model triggers an immediate veto.
2. Observability: unpacking the "why"
A production system must answer one clear question: Why did the agent make that decision? Traditional application logging is wholly inadequate for debugging agentic systems. You need deep tracing capabilities, built directly into frameworks like Langfuse or LangSmith, to reconstruct the complete execution path.
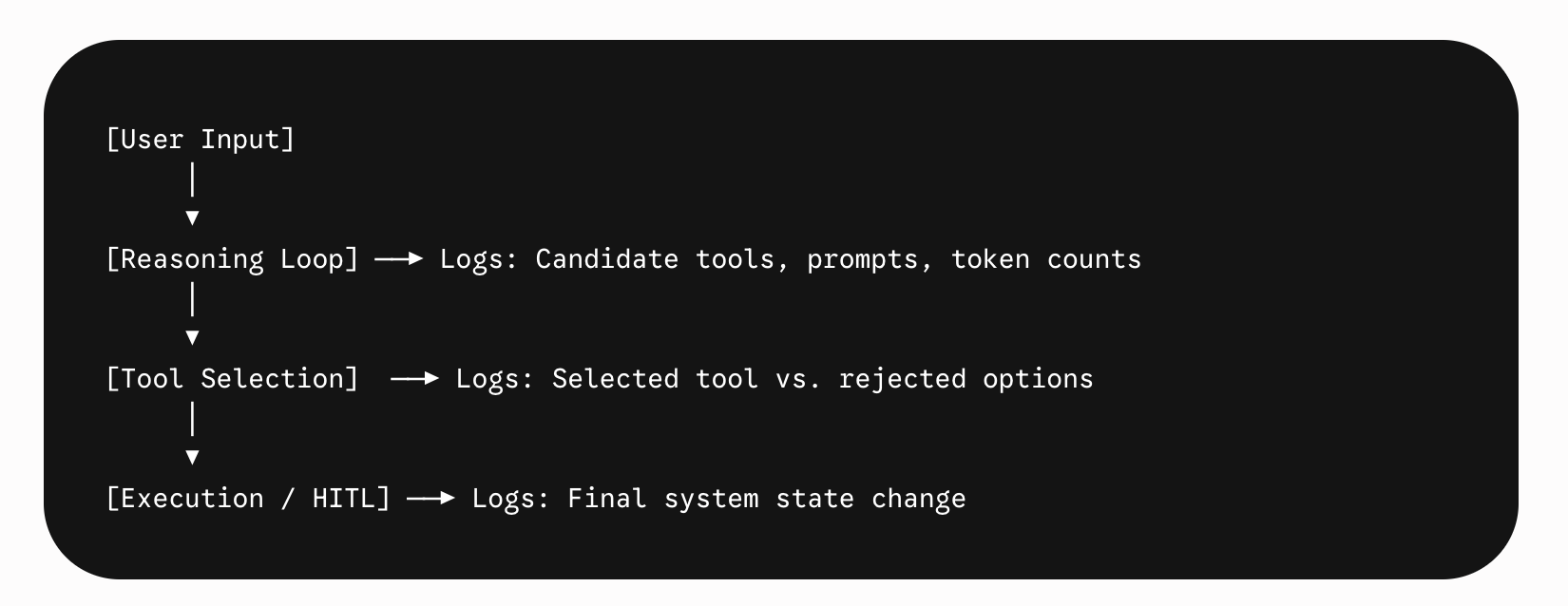
Your backend must explicitly log the prompt states, the full list of available candidate tools, the precise selection criteria, and the raw outputs.
The most effective pattern to improve both system accuracy and observability is forcing a structured reasoning step directly into the LLM payload. Before selecting a tool, the model must explicitly write out its internal logic ("The user requires X data, which resides in system Y, therefore I will call tool Z").
This thought process serves as an internal anchor for the model, but it also creates an invaluable audit trail for the developer. If a human operator needs to approve a HITL request, displaying this reasoning block gives them instant context without requiring them to parse the entire raw conversation history.
3. The operational math: cost and latency
Every architectural choice introduces a trade-off between execution speed, budget, and reliability. Every internal reasoning loop, secondary validation check, and parallel model call adds computing time and dollar costs.

Managing this overhead requires defensive backend strategies. You must use smart model routing, like, sending simple tasks to smaller, faster models and saving frontier models for complex planning. You should also use parallelization for independent verification checks and set up aggressive caching mechanisms for repetitive system prompts.
Ultimately, your architecture depends entirely on your target audience. For back-office automation tasks, users will gladly trade speed for absolute accuracy, allowing you to use complex step decomposition and multi-model consensus loops. For user-facing features, latency is your primary constraint; you must streamline your guardrails, optimize your context, and keep the interaction loop incredibly lean to prevent the user experience from stalling.
What backend readiness for agentic AI looks like in practice
At a minimum, this starts with clarity around the process itself. I believe every company thinking of agentic AI should be able to answer these questions:
- Is there a clearly defined workflow to automate?
- Did we map out all possible scenarios?
- Do we know how the agent should react to specific inputs, which tools it should call, and what a valid output looks like?
Without this level of definition, the agent would improvise rather than operate consequently.
The next layer is integration.
Which systems does the agent need to connect to? Tools like email, calendars, ticketing platforms such as Jira or ServiceNow often already provide ready-made connectors through standards like MCP. When those exist, implementation becomes significantly faster and more maintainable. When they don’t, teams need to build and maintain those integrations themselves.
It’s also important to check if the model can safely access the data it needs. In some cases, legal or contractual limitations prevent sending data to external APIs. That decision (whether to use external models or deploy locally) affects both the infrastructure and architecture complexity and cost.
Demos aren’t always a guarantee of performance
Agentic demos are convincing for a reason, i.e., they run in ideal conditions. Limited tools, clean data, short workflows, predictable outputs. Production looks nothing like that. Inputs arrive incomplete and the number of possible paths grows fast. I've never seen a 100% reliable LLM-based workflow in practice.
The real test lies in reliability. When working on systems, I pay less attention to whether the agent solves the task once, and more about how the system holds up when things go wrong.
How to approach backend readiness in practice
At STX Next, readiness assessment starts with how the system behaves under real conditions. This means analyzing execution traces, running workflows repeatedly on the same dataset, and using non-determinism to surface the edge cases that matter most. A focused evaluation set of around 50 well-defined test cases is usually enough to find patterns early.
From there, improvements follow the evidence: refining tool behavior, adjusting prompts, adding guardrails, or introducing simple structural validation that feeds back into the system automatically.
On the infrastructure side, agentic systems are often lighter than teams expect – standard cloud environments handle most setups well. What we focus on more is control: visibility into what the system is doing, constraints on how it behaves, and a clear path for when things go off track.
It’s important to remember that LLM is a component of agentic AI, and the system is what ships – and what either holds up in production or doesn't. If you're exploring agentic AI, the most useful first step is an honest assessment of whether your backend, integrations, and control layers are actually ready. That's where the real work is, and where most projects either gain traction or stall.






